Agent Guardrails: エージェントに安全性とコンプライアンスのルールを適用(ベータ版)
使用しているエージェントの数がわずかであれば、ビルトインの安全性チェックなしでよい場合もあるかもしれません。では、Agent Workbenchを活用していくうちにエージェント型アプリのリリースが増えた場合はどうでしょう。不適切な言葉のブロックや、個人情報のフィルタリング、プロンプトインジェクションの防止、AIの利用に関する社内ポリシーの遵守をどう行っているかといった、基本的な情報さえも把握するのが難しくなっていきます。
今回のリリースでは、Agent WorkbenchがエージェントのLLM呼び出しの入力と出力をビルトイン検証できるようになりました。これにより、ガードレールを後付けするのではなく、プラットフォーム内で直接適用できるようになっています。
また、ガバナンスとコンプライアンスを大規模にサポートできるよう、組織側で有効化した事前定義済みの安全ルールを、開発者側で個別のエージェントに適用できる仕組みを用意しました。これは、現時点で制御性と信頼性を確保するとともに、今後さらに高度な必須のガバナンスを築いていくうえでの基盤となります。
Agent Guardrailsの紹介
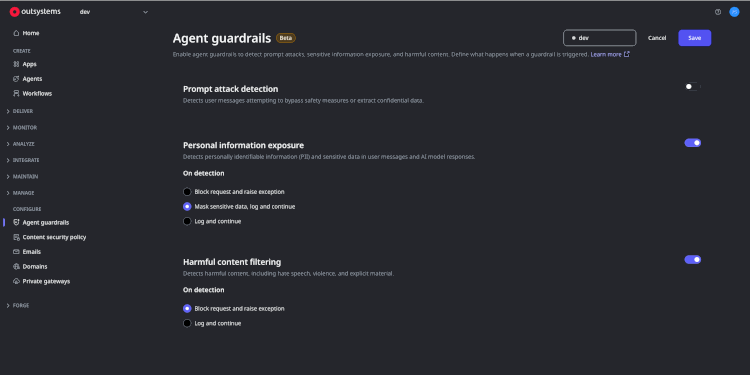
Agent Guardrailsは、安全性・コンプライアンス制御機能です。AIエージェントが受け取れるもの(入力)と生成できるもの(出力)を検証することで、リスクを抑制しながらエージェントの利用を拡大できます。システム管理者が構成できる事前定義済みのガードレールには以下のようなものがあります。
- コンテンツ安全性チェック: プロンプトや回答に含まれる有害なコンテンツ、安全でないコンテンツ、ポリシーに違反するコンテンツを検出してブロックします。
- PIIフィルタリング: 機密データ(個人情報など)を識別し、マスキングまたはブロックして漏えいを防ぎます。
- プロンプトインジェクション対策: 指示の上書き、データの抜き取り、エージェントの挙動の操作といった試みを検出します。
エージェントの実行中、Guardrailsは入出力を有効なルールと照合して自動的に検証します。ルール違反があった場合、システムは以下のような対策を実行します。
- 回答のブロック
- 機密性の高いコンテンツのマスキング
- イベントのロギング(構成に基づく)
適用されたルール、事象、チェック結果などを示した診断も提供されるため、ポリシーに照らし合わせてすばやくエージェントの挙動のトラブルシューティングや検証を行うことができます。
Agent Guardrailsは現在、ベータ版として公開されています。ぜひお試しのうえ、フィードバックをお寄せください。近いうちにさらに改良を加えたものをリリースする予定です。


