The first agentic development experience built for the enterprise
By operating within your enterprise context and guardrails, Mentor helps teams build and evolve systems while maintaining architecture. Describe what you want to build or change in the IDE, and deliver faster without hidden risks.
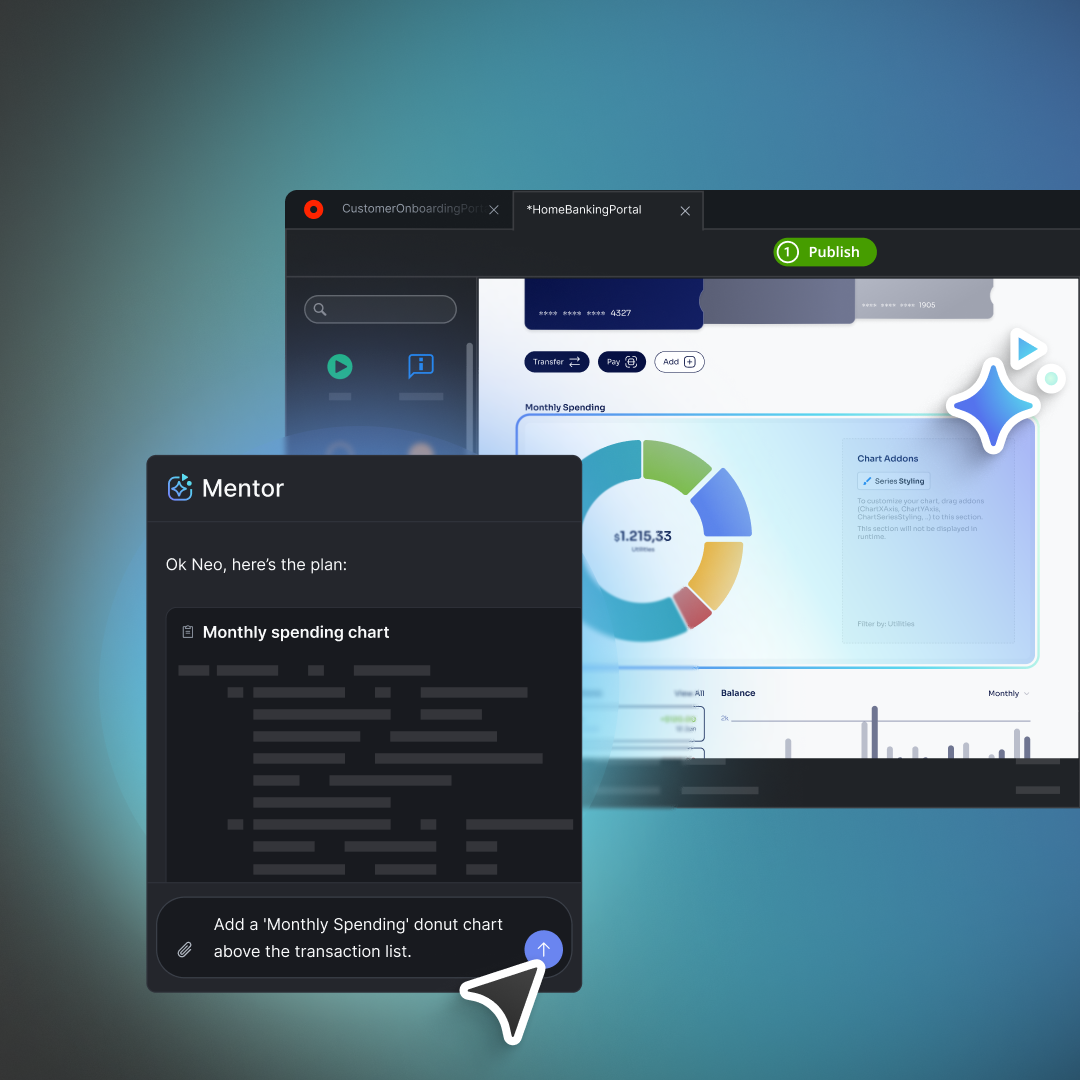
Your SDLC, made smarter and faster with AI agents
OutSystems Mentor brings the speed of AI and the precision of visual development together in one trusted, agentic-first environment—eliminating the fragmentation of standalone AI app builders and coding agents.
By orchestrating specialized AI agents, Mentor automates complex work across app generation and in-IDE iteration while ensuring every step is backed by built-in governance, deep enterprise context, and complete human control. By elevating every developer into agentic systems engineers, Mentor helps teams architect, build, and evolve the agentic systems of tomorrow.
Built on the Enterprise Context Graph: Gives a real-time understanding of architecture, apps, data, and dependencies.
Model-driven development: Maps visible components and hidden dependencies so changes are easy to review and safe to evolve.
Secure and governed at every step: Applies built-in governance, review controls, and traceability to align with standards.
Generate and modernize apps fast with full control
Transform ideas and legacy processes into full-stack, agent-ready apps. Just chat and share your vision or requirements doc—Mentor handles the rest.
Generate apps with your data model and integrations wired in, so your teams can ship faster with less rework.
See exactly what Mentor is going to build and ensure alignment with editable, visual blueprints.
Use Mentor to transform legacy apps into modern, agentic systems that are compliant and secure by design.

Architect production-ready outcomes
Partner with Mentor in the OutSystems IDE at every step to co-architect solutions and shape changes that meet enterprise standards.
Request a complex change, review Mentor’s implementation plan, and give final sign-off before applying updates.
Evolve safely knowing AI is grounded in a shared foundation and never breaks or refactors code that’s passed human reviews.
Offload repetitive tasks and reuse assets so you can prioritize high-value engineering.
Validate in real-time using AI-assisted reviews
Deliver predictable, surprise-free releases with automated code reviews, built-in governance, and real-time observability.
Tame AI sprawl by managing your entire portfolio on a proven platform with full traceability and role-based access control.
Deploy changes with confidence across Dev, QA, and Prod using one-click publishing and human-in-the-loop approvals.
Keep your app’s architecture, security, performance, and maintenance on point without the hassle.

Explore more resources on agentic-first development.



Deliver mission-critical AI faster, safer, and at scale
Discover what agentic AI development can do for you.
Break free from prompt-only AI tools
Move faster with full control over UI, logic, and app behavior using the combined power of agentic AI and rapid visual development.
Compress the SDLC
Cut SDLC tasks from hours to minutes across planning, implementation, and validation, so you can focus on complex problems.
Prevent architecture drift
Build on the Enterprise Context Graph to maintain architectural consistency, reduce rework, and scale safely.
OutSystems Mentor FAQ
Mentor is the first agentic development experience built for the enterprise, providing conversational AI that powers the entire software development lifecycle (SDLC). Powered by the OutSystems Enterprise Context Graph, which provides a real-time understanding of your enterprise architecture, Mentor delivers Agentic Systems Engineering directly within the OutSystems platform, empowering teams to build and evolve systems fast with built-in architectural coherence.
Whether you are turning conversations into production-ready AI solutions or refining features directly in the OutSystems IDE, Mentor plans and executes complex development tasks, automates tedious SDLC work, and frees you to focus on harder problems and higher-value innovation. And with automated code reviews, built-in approvals, and real-time observability, you can ensure every AI-driven change is governed.
Mentor combines agentic AI with traditional AI capabilities such as machine learning, automation, and scanning. Generative AI is part of the experience, but the real differentiation comes from Mentor’s ability to orchestrate specialized AI agents that support the full software development lifecycle, including management, operations, and governance in one platform.
Inside every OutSystems environment, there has always been a living model of your enterprise data, applications, business logic, and governance policies. The Enterprise Context Graph takes this unique contextual architecture and supercharges it, providing the exact dynamic tooling that AI agents need to be highly productive, safe, and effective across your most complex systems.
Instead of starting from scratch, you can use natural language to describe a complete application idea, like "build an employee onboarding app." Mentor will then assist you by creating a visual blueprint so you can see exactly what it is going to build. Mentor then generates the core structure, screens, and data models for you to build upon. But it doesn’t stop there—you can chat directly with Mentor in the IDE to evolve UI and logic, making complex changes and refinements through a continuous conversational experience. Customers across highly regulated industries are using it to build mission-critical solutions—from citizen service and investor portals to supply chain management applications, underwriting and policy management platforms, and patient management systems.
Unlike many AI app builder tools, OutSystems Mentor is designed for enterprise-ready software delivery, not just fast prototyping. Its model-driven foundation brings precision and consistency to AI-generated work, while its enterprise context ensures every app and change aligns with your systems, data, APIs, and governance standards. This gives teams a faster path to production-ready applications that can be trusted, governed, and scaled.