Get to know low-code

Asynchronous vs. synchronous programming: what's the difference? Developers can write software applications efficiently and quickly by using asynchronous and synchronous programming techniques. Despite their similarities, both methods have important differences to consider when deciding which method is best for a particular project. The purpose of this article is to help you make an informed decision about which approach suits your needs by explaining how each technique differs from one another.

What’s the Difference Between Synchronous vs. Asynchronous
Before we jump into the juicy stuff, let’s start by defining the difference between asynchronous and synchronous programming.
What Is Synchronous Programming?
In synchronous operations tasks are performed one at a time and only when one is completed, the following is unblocked. In other words, you need to wait for a task to finish to move to the next one.
How Does Asynchronous Programming Work?
In asynchronous operations, you can move to another task before the previous one finishes. This way, with asynchronous programming, you can deal with multiple requests simultaneously, thus completing more tasks in a much shorter time.
Asynchronous programming is often related to parallelization, the art of performing independent tasks in parallel, that is achieved by using — you guessed it — asynchronous programming.
With parallelization, you can break what is normally processed sequentially, meaning break it into smaller pieces that can run independently and simultaneously. Parallelization is not just related to processes and capabilities but also with the way systems and software are designed.
The biggest advantage of applying parallelization principles is that you can achieve the outcomes much faster, making your system easier to evolve and more resilient to failure.
When to Use Asynchronous vs. Synchronous Programming?
You should only use asynchronous programming if you’re dealing with independent tasks.
When designing a system, here are a few considerations you need to have to define which programming models you should use:
- Identify the dependencies between processes
- Define which you can execute independently
- Define which needs to be executed as a consequence of other processes.
Should You Choose Asynchronous over Synchronous Programming?
In one word: no. Although the benefits are aplenty, not all processes should follow parallelization principles and execute asynchronously. Let’s explore when you should apply asynchronous programming and when sticking to synchronous execution is the best option.
Take a look at the image below. On the top, you can see that in synchronous execution, the tasks are executed in a sequential way; the products are the first to be executed, then customers, and finally orders.
Asynchronous vs. Synchronous.
Now, imagine that you concluded that customers are independent of products, and vice-versa, but that to execute orders you need the information from products first—there you have it, a dependency. In that case, the first two tasks can be executed asynchronously, but orders can only be executed when products are completed—so, they need to work synchronously.
As a result, by applying parallel computing and asynchronous programming when dealing with independent tasks, you’re able to perform these tasks way faster than with synchronous execution because they’re executed at the same time. Thus, your system releases valuable resources earlier and is ready to execute other queued processes faster.
How to Design a System that Runs Asynchronously?
Designing a system that follows asynchronous programming principles can be quite complex, so I’m going to show you how to do it using a typical claims processing portal. Something like this:
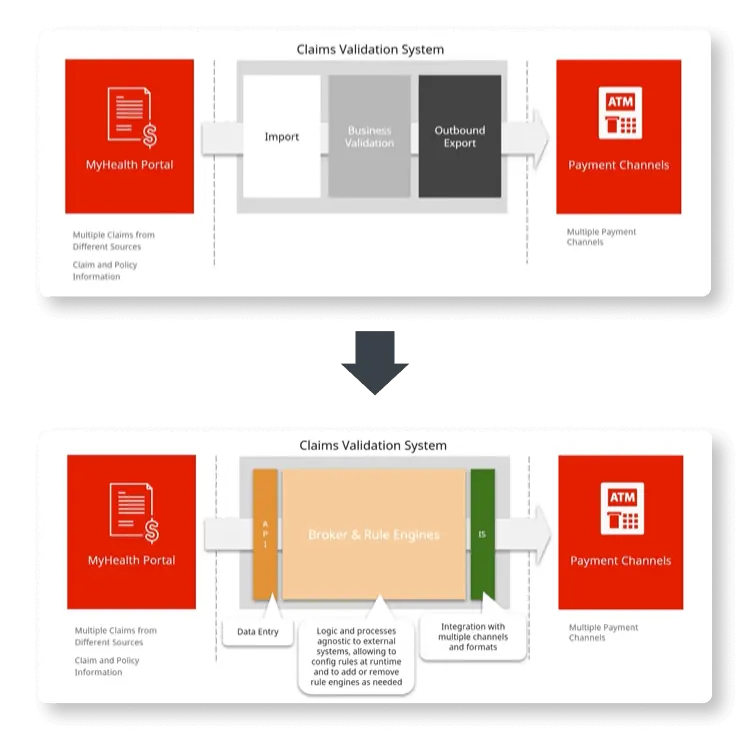
Here, we have the portal that policyholders and other entities use to insert and manage claim information. This portal communicates with a claims validation system through an API.
Looking in greater detail, the validation system imports data to a business validation engine that includes a broker and business rules whose processes and logic are agnostic to external systems. Then, this system integrates with payment channels to where it exports the outcomes of the business validation.
As I said in the beginning, I will explain how to design this system to run asynchronously using a low-code platform—OutSystems. If you’re not an OutSystems developer or architect, you can still use this demo to automate parallel asynchronous processes with your preferred technology.
As we're almost there, I want to clarify a few terms and capabilities I'll be using because I'm using OutSystems. If you’re already familiarized with them, or you simply want to see the proposed architecture to improve the efficiency of this claim portal, you can skip to the next section.

Automating Asynchronous Processes of a Claims Processing Portal: Suggested Architecture
Let’s zoom in to the claims validation system:
The API is going to insert each of the claims into a staging data. Then a timer, that is scheduled, is going to look into those claims. Note that each claim is a structure that can have multiple records inside. So, the timer is going to validate and decompose those claims and records and perform a Bulk Insert into the business entities for the claims.
Now, we want to be able to optimize our resources as much as we can. For that reason, we won’t process each of the records as soon as they’re inserted into the table. We also want to remove the overhead of starting a validation process, so we’re going to use a bucket control, which is basically a record where you’re going to specify which is the initial record and which is the end record. So, this bucket is basically an interval of records and claims that are going to be processed.
With that, for each bucket record, we’re going to trigger a light process that will process each of the records inside the bucket. By processing I mean applying the rules. These rules are engines that can be plugged and played, so they can be added at runtime into the system.
Once a record is processed, if it’s considered valid according to the business rules, it will be set as such and a timer will aggregate the data and send it to the channel accordingly.
That said, here’s our proposed architecture:
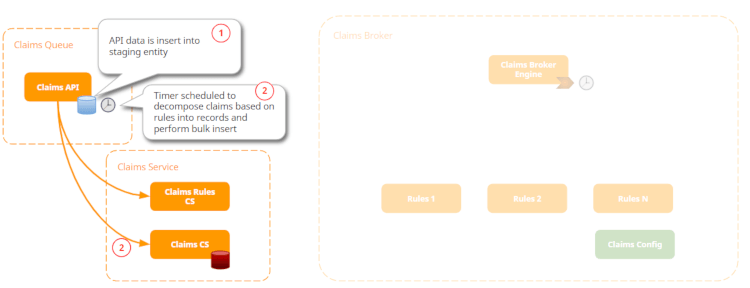
First, the Claims API will collect all the data that is imported through a JSON structure or XML. Each data is then inserted into the staging entity. The goal here is to speed up the data insertion and prevent losing data.
Once the data is inserted, a timer is launched on a scheduled basis. The purpose of this timer is to decompose claims based on Claims Rules previously pre-defined and perform the Bulk Insert. Based on those rules, the claims will be inserted in the Claims Service.
The number of records inside each bulk is the number of records you can process within a three-minute limit. At this point, you should avoid having parallel capacities still available and only run one light process at a time because you are specifying a bucket with a large number of claims inside.
Once the bucket control is created, then a light process is triggered.

And the triggering is going to execute the process.
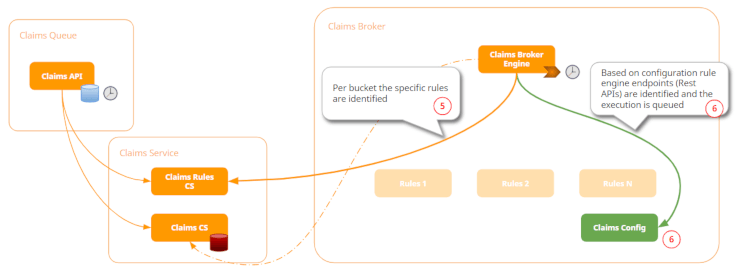
As a result of each rule, a claim will be considered “valid” and thus proceed to the next step, or “not valid” and, in that case, rejected by the system.
Finally, the system will have a timer that based on priority is going to get all the valid claims, aggregate them, and send them to payment channels.
You can also make the prioritization rules more complex. For example, you may want to define that certain claims should be sent as soon as possible so they would need to be sent right after the system validates them and are ready to be paid; or you may want to define certain claims as low-priority and, in that case, can be processed by the timer.
Another benefit of using this type of step-by-step rules in the engine is that the system can also recover from a timeout or even a crash. Imagine that after processing rule one but before executing rule two, there's a timeout or a catastrophic failure in the process and the system needs to recover from it. With this system, each of the claims is available to recover from the exact point where it was before the incident. So, in this case, the claim would recover and execute rule two instead of repeating rule one.
Key Takeaways
I hope this article helps you clear up any questions you may have about when you should use asynchronous or synchronous programming. To wrap it up, here are the main key points:
- Use the asynchronous techniques that are more suitable for the outcome.
- Scale front-end servers and configurations to fit your needs. Remember that when you go into millions of records, you need more front-end servers to accomplish your needs.
- Design with flexibility in mind and avoid hard-coded values or site properties. Imagine you use hard-coded values for bucket control; if your claims validation process becomes slower and you’re not aware, you start having timeouts. Now you’re in an even worse situation because you need to publish the changes and not go into a back office to change them.
- Don’t over-engineer. Try to keep your architecture and system as simple as possible.
If you want to see this scenario in action, take a look at my recent TechTalk, How to Use Asynchronous Techniques in OutSystems. There, I will show you the solution proposed here while leveraging the OutSystems asynchronous capabilities, fostering scalability and resilience to failure and ready to handle large data volumes.



