Overcoming Data Migration Challenges to Keep App Development Moving
One of the most underrated tasks during software development is having the ‘right’ data in the ‘right’ environment. A lot of time is spent in manual markup to create specific situations. Manual entry is an extremely extensive and error-prone affair.
Ideally, tooling is used to move representative data to acceptance or test environments. In many cases, the target environment already contains data. It’s preferable to keep or update data that is already present in the target environment. This is not a trivial matter. How do we ensure that test data is retained while missing data is replenished if necessary?
The Data Migration Process
Using practical examples, we will show how automation can be applied in your data migration strategy.
Suppose we have an application that registers customers. In the figure below we can see that customers Alan and Becky are present in the production environment while Alan and Tom are present in the test environment. As we move data from Production to Test, we expect to amend Alan’s data in case of any changes, add Becky’s data in the test environment, and leave Tom’s data unchanged.
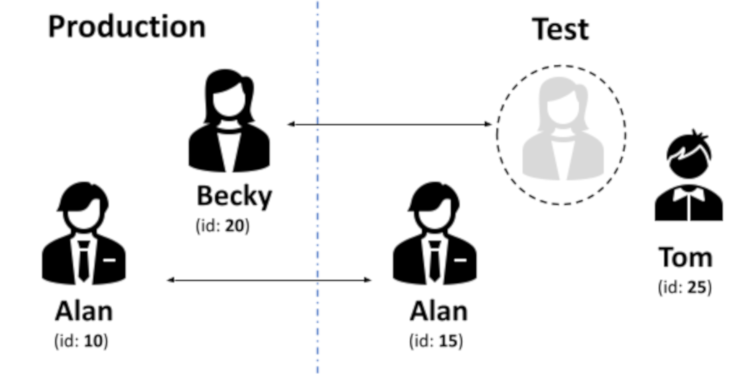
At first, this seems easy to achieve by simply moving customers Alan’s and Becky’s data. However, a complicating factor is the use of “Autonumber Identifiers”, as is generally the case in OutSystems environments. As a result, the same records often have different IDs in different environments.
In our example, Alan's ID in Production is 10, while in Test it is 15. So it is impossible to match customer records based on these IDs. If we fail to take this into account, then this will result in the creation of a new customer record for Alan, and he will be registered twice. If we transfer data a second time, we will have a third record for Alan, which makes it even harder to find the correct one. That is something we want to avoid.
We can expand on this example because, alongside the customer information, we also want to move order information. The Order entity holds the order information and it has a foreign key attribute for the customer as well as a SequenceNumber attribute that is unique per customer.
If we want to transfer Becky and her orders to Acceptance, we need to:
- Create customer Becky (with a newly generated ID of, for example, 30);
- Create Becky’s orders;
- Link these orders to Becky by populating the foreign key with the value 30.
To do this successfully, we have to take the following into account.
1. ID Mapping During Data Migration
In the production environment, Becky’s ID is 20. When we moved to the test environment, her ID became 30 (in this example).
So in general, we need to keep track of IDs of the migrated records (the old and the new ID) to correctly generate the foreign keys (in this case the orders of Becky).
2. The Sequence to Add New Records
Before we can create Orders, we need to have a customer. So, the relationships between entities determine the sequence to add new records. It is crucial to determine the correct sequence before migrating data, therefore topological sorting of the data is required.
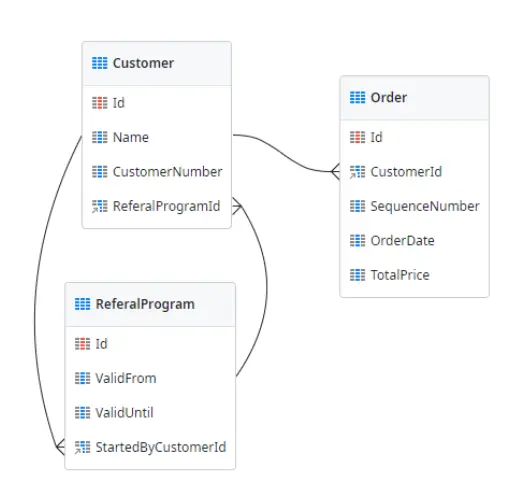
In some cases, we are dealing with circular relationships, in which an entity has a direct relationship to itself or an indirect relationship through multiple entities.
The solution to this problem lies in ensuring that at least one of the relationships in this circle is optional. We can insert the relevant records and assign a NULL value to the optional foreign key. After adding all the records, we update the NULL value foreign key to the correct value.
3. Matching Records During Data Migration
Matching a record means finding a corresponding record in the target environment. Because a customer cannot be matched using the technical ID, this has to be done based on a combination of several other attributes within that entity: the functional key.
In our example, this could be the CustomerNumber for the Customer. For the Order entity, it will be the SequenceNumber in combination with the foreign key to Customer.
When transferring the data in the data migration process, the functional key can be used to check whether the record is already there. In that way, we establish that Alan is already present in the test environment, while Becky is not.
For entities with ‘non-autonumber’ IDs, matching can be done based on an ID attribute, if required. However, this might not always be the case, since, for example, one can add a record in the Test environment with ID 50 and add the same record in the production environment with ID 51. Therefore, knowledge of the data model and use case is necessary to ensure a correct data migration.
Static entities also have to be matched because they can have different IDs in different environments. However, it is not necessary to define a functional key for static entities.
Matching can be done based on information in the system table ossys_entity_record as this table holds the ID for each record in that particular environment.
Removing Complexity from Data Migration Through Automation
Although at first sight, it may appear to be relatively easy to move data, it most certainly is not. We have to take numerous hurdles to successfully complete the data migration process.
For that reason, CoolProfs has developed the Cool Data Mover to support your data migration approach. This tool provides a smart solution for moving data between OutSystems environments from and to cloud/on prem installations.
Learn more about the Cool Data Mover and the successful data migration approach in the coming blogs on automated data migration.
In collaboration with: 



