AI Deep-Dive: Part 2 - A Quick Look at Graph Neural Networks
This blog post is the second part of a series that introduces you to neural networks and talks about the common scenarios where they come in handy. In the first part, we described networks that work with numeric data, image data, and sequence data. Usually, these forms of data are sufficient for addressing the most common use cases. Predictions on how certain values (such as temperature and local population) influence other quantities (such as beer consumption) involve numeric data.
We saw in the previous blog post that image recognition problems are frequently found in the world of machine learning as they are difficult to describe programmatically but are easier to demonstrate via examples and illustrations. Similarly, sequences, whether they be of text or sound, fall under the same bracket of machine learning problems. In this blog post, we will introduce a particular kind of data structure that does not fit any of the above categories — graphs.
Connections are everywhere in the real world. Graphs are useful when representing real-world data where connections are important because, with graphs, the data and their relationships are of equal importance. The connections between things provide us with additional information, for example, a connection between two bank accounts.
Graphs literally ‘connect the dots’ for us, and can be used to identify connections in data. There are many potential use cases where identifying hidden connections in data can make a lot of difference, for example, financial fraud and money laundering. You might have heard about the infamous Panama Papers, or the fake bot account detection in social media networks, such as the multimillion Instagram influencer fraud, in both cases graph data identified the hidden connections.
Graphs All The Way Down

At a basic level, graphs are a method for abstracting data and the relationships between the data and are made up of nodes and edges. Nodes represent the data and edges represent their relationships.
Graphs can represent real-life datasets, such as, different systems in physics where nodes are the physical elements and the edges are the forces that act between the elements (planets and gravitational forces.) Here are a few more examples of how graphs can abstract real-life data:
- Friendship relationships - where humans are nodes and the relationships that connect them are edges.
- Knowledge - knowledge graphs are a programmatic way to logically organize knowledge - where knowledge entities relate with other entities in the graph (eg: Lisbon is connected to Portugal by an edge of "capital city of" and Portugal connects to Europe as "country of", ...)
- Chemistry - molecular graphs represent atoms with nodes and chemical bonds with edges, mimicking the structural formula of chemical compounds.
- Web graphs - where nodes represent webpages and edges represent hyperlinks.
- Maps - where cities are nodes and roads are edges.
Both nodes and edges in a graph can contain attributes, for instance, in the maps example. Cities (nodes) can have attributes such as:
- Coordinates - geographic coordinates of an intersection.
- Population - number of people living in a specific city
Roads (edges) can have attributes such as:
- Length - for instance, Waze maps allow roads to have segments of any length, under 10,000 meters.
- Type - there are public roads, private roads, drivable roads, non-drivable roads, highways, and a lot more.
- One-way/Two-way traffic - for instance, you can travel from A to B using a specific one-way street, but you’ll need an alternative road to return to point A.
In computer science, there are numerous algorithms that are specific to graphs. As a result of their flexibility, they’re often more difficult to work with and have not historically been widely used in machine learning, and in particular when it comes to association with neural networks. However, the tides are changing, and graphs in combination with neural networks are too tempting and too powerful to be overlooked any further.
Basics of Graphs, But in Sequence
Sequences are collections of elements listed in a particular order (the order of the elements matters), in which elements can be repeated, appearing multiple times in different positions in the sequence. You can think of a sequence as a basic form of a graph. The elements (nodes) of the sequence are connected by edges to the next element in the sequence, and these edges have the attribute direction.
As we described in the first part of the blog series, we usually address sequences using Recurrent Neural Networks (RNNs). RNNs process each element in the sequence, carrying a state from the previous step to the current step, updating it. The state reflects everything the sequence has shown us so far.

Alternatively, you can think of the carried state as a message that's passed along from one sequence element to the next. Each element in the sequence updates the message to incorporate information about itself so that the message reflects the information in the sequence as it is processed.

If you look carefully, you’ll see that it takes as many steps/elements (called timesteps) as the length of the sequence for a message to collect information about it in its entirety. It might seem as though this is a lot of unnecessary work. However, we could have every element send a message to the next one on each timestep of the sequence. This way, the last element would take the same number of timesteps to gather information about the entire sequence.

Just like we applied the idea of message-passing to sequences, we can also apply it to other kinds of graphs.
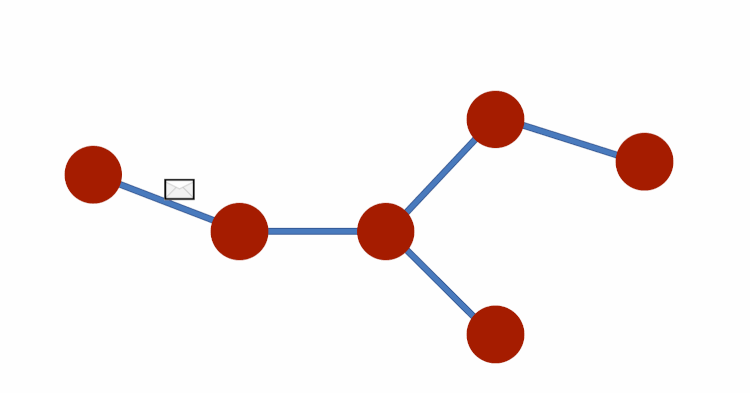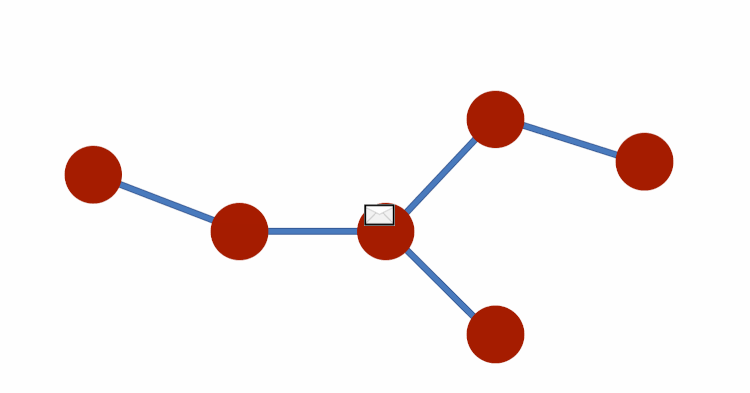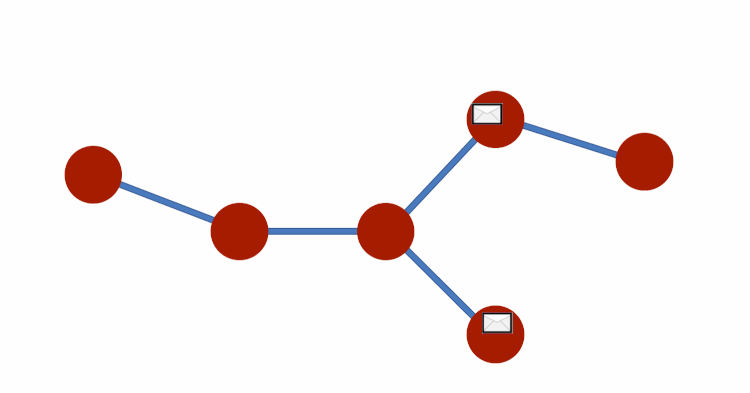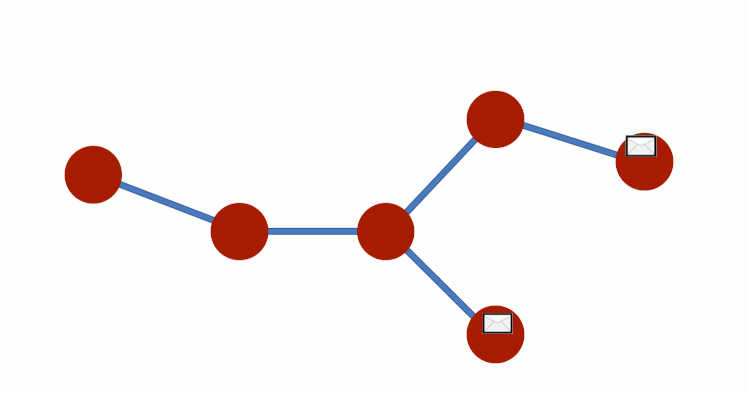
Consider each element is passing messages to the elements it connects to — after a few timesteps with exchanges, each node will hold messages that contain information. And, this information within the messages represents an entire graph.

Notice how the edge structure constrains the way messages are passed. As you know, edges represent relationships and interactions and are a vital part of graphs. The dependency on the edge structure introduces structural bias that influences the messages resultant states. And if the edges also have attributes, these will also influence the contents of the messages, affecting the end result. And this is how we create a Graph Neural Network (GNN).
Code is Text, Code is Graphs

Think of the programming languages that you have used either in school or university. Most of them are text-based. In spite of this, code can actually be best represented by graphs. Even natural languages (human languages like English) are usually processed by an interpreter or a compiler that ends up producing an abstract syntax tree (AST).

These trees (which are also a type of graphs) can convey richer information than what you would get from looking at a portion of the text. For instance, they can easily point out that the x(-s) referred multiple times are in fact the same variable.

Now that you have your code represented as a graph, it’s easier to think of tasks for a neural network to perform. One such task would be to create a hole in the graph - a hole is a node in a graph whose contents have been removed - and then we feed it to a GNN so that it can be trained to predict what was initially in the hole. If the prediction is different from what we expected, it may be a sign that the original content was incorrect. This way, you can create a model that predicts missing or misused variables and operations.

Alternatively, you can predict variables that were already there, and if the model predicts anything differently, this indicates to the developer that there must’ve been some error in the variables.
The potential of these models and the doors that they can open would be unthinkable until not too long ago. You can now identify bugs that wouldn’t be caught by a compiler because the code is syntactically correct and valid with respect to variable types. And it’s not just compilers. Rule-based automatic bug-finding tools would probably also miss these errors. It’s just not feasible to devise rules for every possible scenario.
The Promising Future of Deep Learning on Graphs
As you can see, GNNs open up new uncharted possibilities in dealing with problems that use graph-structured data. We previously discussed how Convolutional Neural Networks (CNNs) have greatly advanced the state-of-the-art in image processing. Similarly, GNNs can now push the frontier further regarding code analysis and prediction, molecule analysis, physics simulations, knowledge graph traversing and so on. This sub-field is only just getting started. There aren’t that many tools that are as polished as the ones you find for CNNs and Recurrent Neural Networks (RNNs). However, this does bring about amazing opportunities for those of us who hope to create these tools ourselves.



