How We Reached DRY land — Detecting Duplicate Code in a VPL
I don’t mean to be dry, but if you’re a software developer you know you should be. Especially when it comes to duplicate code.
DRY, the abbreviation of “don’t repeat yourself,” is a term coined in the late 1990s by Andy Hunt and Dave Thomas in their book The Pragmatic Programmer. The now-famous software development principle stands for the reduction of repetition in the code. It will save you effort, prevent mistakes, and keep you out of the WET — We Enjoy Typing — team.
The problem is, even if a given developer is as dry as a martini, the duplication of code often occurs when different developers work simultaneously on the same program. Chances are, you might be implementing something that someone has already implemented before.
Why is this a problem? It all comes down to maintainability. If you ever find a bug in that piece of duplicate code, it is very likely that the bug will be present in all its repetitions. If you need an additional feature, you might forget to update it in all your instances of duplicate code. In sum, you will never reach DRY land.
Now, if you work with a visual programming language (VPL) like OutSystems, you could detect duplicate code the same way you would in a text-based language but the visual structure of the code that would allow you to highlight the duplication would be lost. You have to keep it visual to be able to show the user where exactly the duplication is taking place.
Cue in subgraph matching, a technique that highlights matching graph elements. In OutSystems, logic is implemented through logic flows. Logic flows are graphs, thus a duplicated code pattern is a common subgraph occurring across multiple flows. However, subgraph matching is slow, costs a lot of computational cells, and is not scalable.
We shared how we solved this problem and the algorithms we used in a scientific paper we published, but there was a lot of previous code pattern mining work to make this happen. Let’s dive into it.
Tackling Duplicate Code in a VPL
First, duplicate code is not all the same. While some parts of the code can be considered duplicates because they look identical even if they don’t refer back to the same source, there’s also duplicate code that actually looks different but leads to the same action. Same semantics, different syntax.
At OutSystems, we decided to tackle a specific type of code duplication in which the graph structure was completely identical with only a few minor changes allowed within each node, such as if expressions, assignments, and aggregates (how you access the database).
As high code has been around longer than low code, we were among the few navigating the problem. There’s some work on duplicate code in model-driven engineering systems, such as Simulink models, but this is otherwise a relatively unexplored field.
The problem of duplicate code first stood out in a conversation with the AI Mentor team. The AI Mentor Systems is a tool that helps users programming with OutSystems to manage technical debt throughout the development lifecycle.
There were many debates about the kinds of logic and action flows repeatedly created by developers using the OutSystems platform. We began thinking of ways to explore them to help us evolve and guide the evolution of our programming language.
As Lead Research Scientist, I had done previous work, along with other members of the AI team, on algorithms for mining common subgraphs from an OutSystems code base or code bases. The foundations of this work would then lead to our duplicate code functionality. But more on that later; let’s start at the beginning.
Doing the Background Work
A big part of solving this problem was simplifying it. Pattern mining simply consumed a lot of our time as we tried to find all the duplicate subgraphs in the action flows in our VPL. Therefore, we resorted to finding the fully duplicate flows first because it’s much easier to prove that two logic flows or graphs are exactly the same than to compute a maximum common subgraph between them.
If you usually work with high code and don’t think of code as graphs, think of it like this: first, we tried to find all the duplicate code parts inside a function. Then, we realized it would be more effective to check first for entirely duplicate functions. This is a much simpler task than carrying out an exhaustive comparison of the function’s parts or code snippets, or in other words, subgraphs.
In sum, we had to find a way to reduce the number of flows or graphs: we checked which flows in a given code base were exactly the same and picked one per identical group — this alone led to an average 20% reduction in the number of flows, which resulted in a 35% reduction in the total mining time.
In fact, subgraph matching was only part of the problem — it computed a single common subgraph of two logic flows. To actually mine these common subgraphs, we had to optimize what we call our “greedy pattern miner” algorithm on the resulting “de-duplicated” set of flows. This works like a black box, receiving the entire code base and comparing the many pairs of flows, mining several common subgraphs from a code base.
But first, let’s go back to subgraph matching. What we did was turn subgraph matching into an automated reasoning problem that could be solved with the help of an open-source tool called PySAT. Luckily, I am familiar with many of the automated reasoning tools that came out in the last few years, so we jumped over this barrier of finding a suitable tool pretty quickly.
As requirements, we left out accelerator flows, which are generated by the OutSystems platform. In addition, we defined the nodes to be considered, discarding nodes that aren’t refactorable, such as Ajax Refresh nodes, as well as those that access widget properties. Aggregates in preparations were also excluded as these are visible in the scope of the screen instead of just the logic flow.
To build our code mining infrastructure using this automated reasoning tool, we had to:
- Specify what the problem is in propositional logic, the language of the tool.
- Feed the specification to the tool.
- Translate the tool’s solution into a common subgraph.
After being given the specification in the shape of a propositional logic formula, automated reasoning does the work for us, providing us with a solution if one exists.
A Bigger Challenge
In good old software development fashion, the process of fine-tuning this solution was iterative. We validated our decisions every step of the way with users of the OutSystems platform, which was a significant part of this effort.
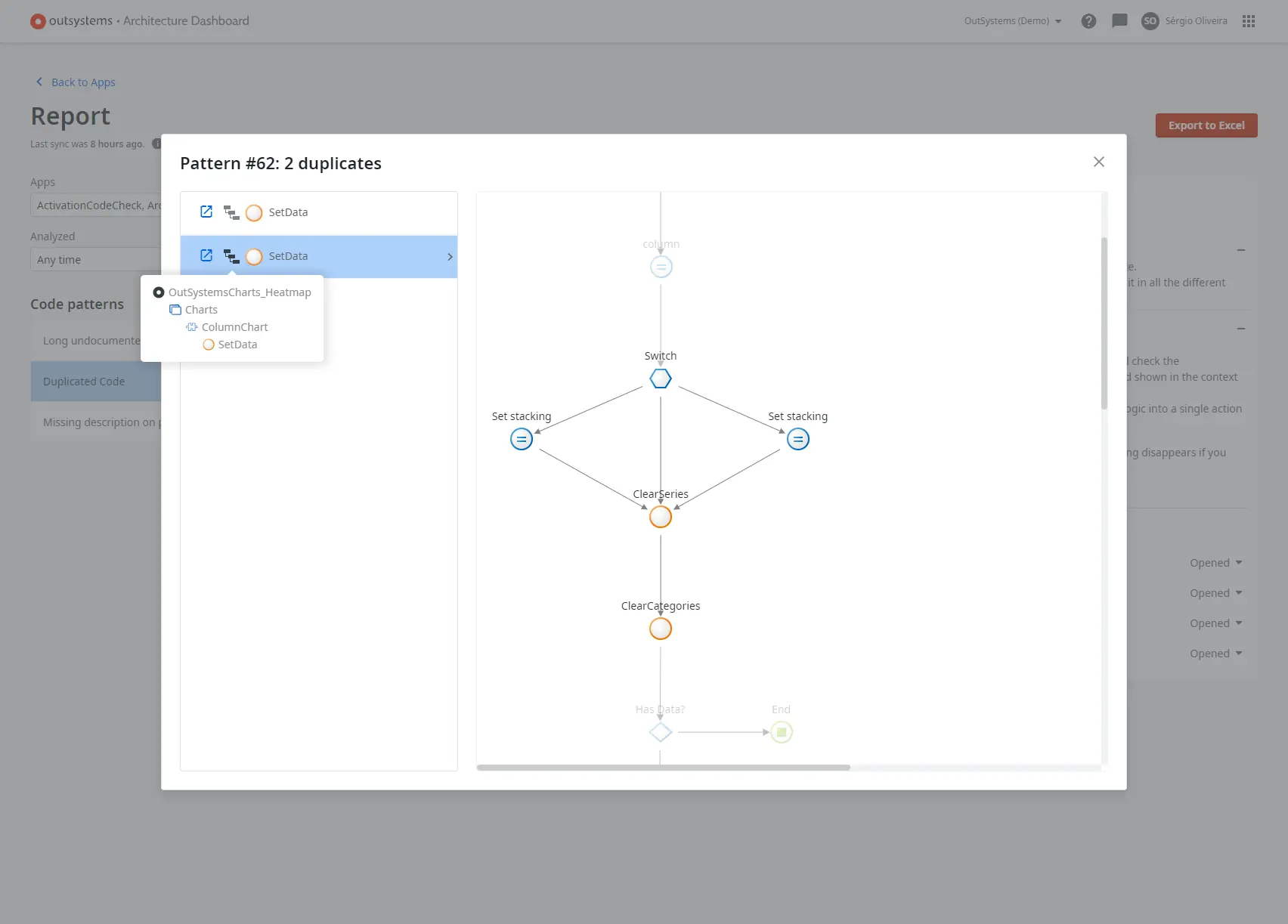
In the meantime, we also got into conversations with the AI Mentor Systems Team who, after watching us mine common patterns for insights, was particularly interested in the special case of duplicated code. Detecting duplicate code could be a way to help developers building applications with OutSystems to steer away from technical debt.
Looking at the OutSystems platform figures, it was obvious this was an issue: the duplication in the OutSystems VPL code base reached as high as 39% in some of the factories as reported by our duplicate code tool. On average, we found 10% of code duplication. There was no DRY land in sight.
Together, we decided to redirect and improve the solution we had found to specifically tackle duplicate code patterns. But, to implement this functionality on the AI Mentor Systems, its team required that the duplicate code system had to analyze all factories in the AI Mentor Systems within a 12-hour limit. The math was simple. The faster it goes, the lower the infrastructure costs to serve this functionality.
Getting Inspiration From High Code
Mining duplicate code patterns with our greedy pattern miner was challenging because we were performing a quadratic number of flow comparisons. This is an issue because you have to compare all flow pairs in order to find the largest, and thus most impactful common subgraphs. In searching for a solution to support high code nodes, I found a technique that precisely addressed this.
In high code, some state-of-the-art detectors rely on a sort of index or mapping of the tokens occurring within the code to the actual code snippets in which they occur. In low code, we have nodes in the code, such as an ExecuteAction executing a ListAppend, and edges between them. Therefore, we mapped out types of edges to the flows in which they appear.
Creating such an index is a relatively fast process and makes matching much more straightforward: I only need to look into the edges that appear in a given flow and then use the index to compare it only to the flows that contain at least one of those edges. This drastically reduces the number of pairs we needed to analyze in all our factories: the total runtime dropped from 20 to 6.5 hours, all running in a single CPU core.
Mining duplicate code patterns now takes less than a minute per factory for most factories, which is remarkable. Of course, there are outliers, but even the most time-consuming factory now takes 50 minutes to process, which is well under the 12-hour deadline imposed by the AI Mentor Systems.
Not only were we detecting duplicate code, but we were also highlighting the common patterns that explain such duplication. And we were doing it in record time.
What’s Next?
Duplicate code pattern mining is an AI Mentor Systems functionality that is now available for developers programming with OutSystems.
While we achieved our goal of figuring out a scalable solution for mining duplicate code patterns in the OutSystems VPL, our work is far from done.
One of the issues we’re now dealing with is the number of false positives, but we aim to enhance the user experience by further refining our duplicate code mining tool.
We believe that there is still plenty of room for improvement and that we will be able to analyze code even faster. Our ultimate goal? A real-time code duplication detection experience in Service Studio. Code duplications are detected as soon as they are written, preventing such duplication from being introduced into the code base at all. Maybe then we will, finally, reach DRY land.


