Your Code Might be Done, but Your Debt Isn’t
We’ve discovered a ton about technical debt since Ward Cunningham coined his metaphor. The most striking idea is that we can accrue debt outside of our codebase with our processes, our interactions, and the tools we use. This broader view of debts explains many of the ways we incur debt in deployment and operations. Think of the debt you incur during deployment and ongoing operations of our software as deployment debt.
Do You Have Deployment Debt?
Probably.
Is there a step in your deployment process that could use a bit more (or maybe even less) automation? Could your staging environment match production a little bit more closely (or become a canary with real production loads)? Is there a metric or two missing that would help you better understand what’s going on in your system?
These are all examples of deployment debt. They may represent conscious trade-offs (good debt), or a place where you cut some corners (bad debt). Just like a financial debt, your technical debt has both principal and interest. Your trade-offs and cut corners and the process they create are the principal on that debt. When things go bump in the night and users are angry, that’s the interest you’re paying.
If the interest is minimal, you may defer paying down the principal indefinitely. Once you start facing severe issues, your interest payments have become too much. Time to pay down that debt. It’s better to understand and quantify the debt before it gets to that, and there are some signs of deployment debt you need to watch out for.
Signs of Deployment Debt
The first sign that you’ve got bad deployment debt is users discovering new bugs in production shortly after a release. These bugs may have been introduced at other points in your process and may indicate other kinds of technical debt. But when defects get to production and users notice them before you do, that’s a sign of deployment debt.
Another is bugs that appear after your new release has been in production for a few weeks. These types of bugs can indicate that there are defects lurking in your systems based on unconsidered edge cases or temporal issues like memory leaks and insufficient resources. You need to have the systems and processes to detect them and respond as early as possible. I’ll also point out that running the same release for a few weeks probably means you can’t deploy quickly enough, another sign of technical debt.
The last sign of deployment debt is not being able to roll back your changes when an issue arises. You may not be able to reproduce the earlier version, understand all the dependencies that need to change, or even be able to change those dependencies because of other issues. All of these are signs of significant bad debt in your deployment and operations processes.
Avoiding Deployment Debt
Like all technical debt, you do not want to avoid all of deployment debt. Taking on debt with a small principal and/or minimal interest can focus your team on more important matters than perfecting their deployment procedures. But as we saw above, not all of our deployment debt is good debt, and it’s essential to have processes and platforms that prevent taking on bad debt.
1. Continuously Integrate and Deliver Your System
Continuous Integration (CI) and delivery (CD) are the first steps to avoiding bad deployment debt. CI/CD doesn’t mean that every last change goes all the way to production—though it’s nice when it can—but it does mean subjecting your changes to integration with other components, automated testing, and deploying to the final runtime environment.
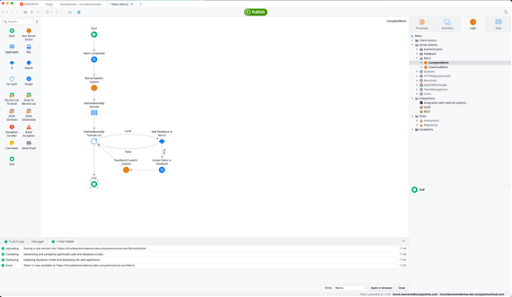
One-Click Publish in OutSystems applies the principles of CI/CD to every single change that a developer makes. The only way to save a change to an OutSystems application is to publish. Each publish, e.g., every save, compares the change against the previous version, stores a new version, builds that version, and deploys it to a development environment.
2. Separate Deployment Environments
Newly released software should not be immediately subject to full production loads. It should first be exercised in a pre-production environment that closely resembles production and is kept equally stable. There are a few different ways to accomplish this, but generally, a pre-production environment that closely mimics production allows for the lowest risk approach. This environment should run the exact infrastructure as production and access the same dependencies.
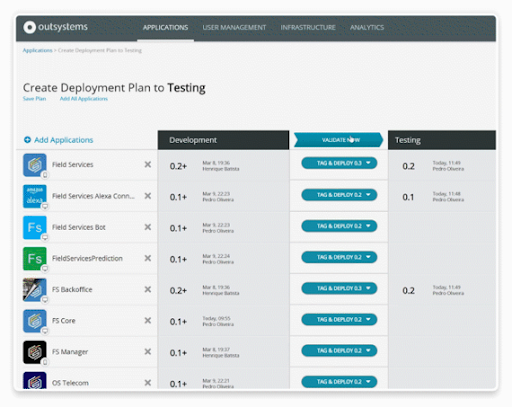
Using LifeTime, OutSystems Cloud customers can create pre-production environment and insert them in the path between development and production. These environments run in the same infrastructure using the same number and types of server instances as their production counterparts. LifeTime assures that applications are only being promoted using a deployment plan that includes all of their dependencies, eliminating a common source of deployment errors. Execution of the plan is fully automated, preventing issues caused by human steps.
3. Add Observability to Your System
Observability is the quality of software that lets you understand exactly what’s going on at run time. Observable software collects and exposes metrics about how it’s operating, and observable systems expose those metrics easily guide monitoring and decision making.
Your deployment debt incurs a massive amount of interest when your users discover issues. The easiest way to prevent these interest charges is to avoid defects getting to production, but since that’s impossible, we want to make sure we find and fix them before they have user impact. The more observable your application, the less likely you are for your customers to find your errors for you.
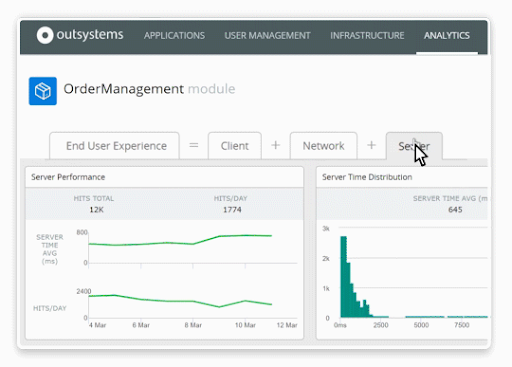
OutSystems applications automatically share their metrics to LifeTime, making those applications observable by default. LifeTime supplements application metrics with systems-level metrics to provide a complete view of application performance. This observability helps you discover and quickly resolve issues.
LifeTime metrics are also available via an API, allowing you to incorporate OutSystems applications into broader dashboards for monitoring by your first-line operations centers.
4. Track Quality Metrics Over Time
Metrics are fantastic for identifying what’s going on, but you need to know what you’re looking at. Did your recent deployment cause a dramatic change in user experience? Is your server performance degrading over time? These are potential signs of deployment debt, but you’ll only notice them if you know what “good” and “bad” look like. You need to keep track of your metrics over time to understand how they change.
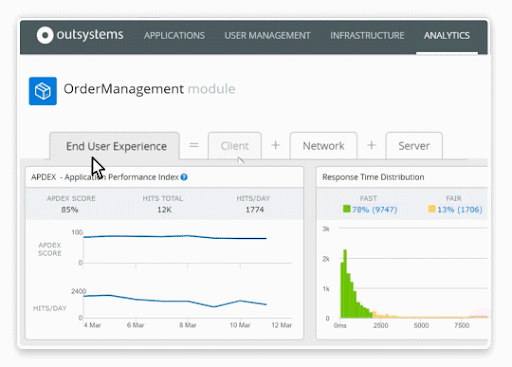
LifeTime tracks metrics over time to highlight anomalies that may require your attention. It also provides insight into how individual page performance has changed over time, identifying pages that are getting slower to highlight problem areas.
5. Facilitate Recovery
The inability to rollback is one of the core signs of deployment debt. A deployment cannot be rolled back if it’s impossible to recreate the previous state of the system, or when it’s difficult to disable a change that’s misbehaving.
Rollback failures can occur for many reasons, but generally fall into a few categories:
- You can’t return to a consistent version across the entire stack. You may need to “fail forward” by making additional updates amid the issue instead of quickly getting back to the previous state.
- You can’t recreate the previous version, either because you didn’t track it or made manual changes outside of your deployment flow. These types of issues are tough to fix by failing forward since you don’t know exactly what’s missing.
- The failure is so severe that a new release cannot be completed quickly enough.
You need a “kill switch” to prevent catastrophe immediately.
OutSystems tracks application versions across all environments, from development to production. Since OutSystems is a full-stack platform, every version includes all required changes—from front-end to database. Each environment tracks a new version for each change it receives, tagging in LifeTime traces which version was promoted and when. Any environment can be rolled back to its previous version, reversing all changes across the stack. OutSystems also tracks when an application is changed outside of development and allows developers to quickly incorporate those “hot fixes” into the application under development to maintain consistency.
OutSystems uses a trunk-based deployment model, meaning every version of an application fully integrates with all other changes all the time. Sometimes a change might not entirely be ready for production traffic, and you’ll need to keep it hidden until it is. Feature flags provide this capability and allow you to turn off a feature released a little too early. Feature flags also serve as kill switches that instantly disable errant changes in a release. Feature flags should be reviewed regularly and removed when the risk recedes.
Want to learn a little more?
Watch our interactive discussion with Professor Rick Kazman, author of “Technical Debt in Practice: How to Find It and Fix It,” and learn best practices to monitor, measure, and manage technical debt.




