NeurIPS (short for Neural Information Processing Systems) is a conference that brings together researchers and practitioners in machine learning and artificial intelligence. It is held annually in December and attracts attendees from around the world. The conference includes oral presentations, poster sessions, and workshops, and it provides a platform for researchers to share their latest findings and ideas with their peers.

Table of contents:
- An Empirical Analysis of Compute-Optimal Large Language Model Training
- RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer
- Confident Adaptive Language Modeling
- Self-Explaining Deep Models with Logic Rule Reasoning
- Coming Up Next
Disclaimer: This intro was generated by ChatGPT. Interested in knowing how ChatGPT was trained? Wait for our next blog post, where we will give you a summary of InstructGPT.
This year, we, the AI team at OutSystems, attended NeurIPS because we had a poster accepted at the Federated Learning workshop. Since there are so many interesting papers on NeurIPS and we cannot read them all, we selected 15 that caught our attention and wrote a short TL;DR with a summary so that you don’t have to go through all the 2834 accepted papers.
We will divide the 15 selected papers into 3 blog posts, and this is the first post. If the paper was awarded one of the best papers, we add a star (*)).
Let’s get started!
1. An Empirical Analysis of Compute-Optimal Large Language Model Training (*)
- Author: Hoffmann et. al.
- Link to paper.
TL;DR: The researchers argue that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models while keeping the amount of training data constant.
Furthermore, by varying the model size and the number of training tokens, they empirically found out that for compute-optimal training, you should scale the model size and the number of training tokens equally.
To test this out, they constructed Chinchilla to have the same compute budget (same FLOPs cost) as Gopher, but sacrificing model size for more training tokens (Chinchilla has 4x less parameters than Gopher but 4x more training data).
The results greatly confirmed their hypothesis as Chinchilla outperformed Gopher and several other larger (compared to Chinchilla) models on a variety of downstream tasks.
Problem: Large Language Models (LLMs) have billions of parameters, but training them takes a lot of time, and computation power. Researchers are expecting new state-of-the-art results by training larger and larger models while keeping the training set at 300 billion tokens. But is increasing the model size and not the training data the right way to go? Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens?
Empirical Studies: They explored three approaches to answer the question, “Given a fixed FLOPs budget, how should one trade-off model size and the number of training tokens?”.
The three produce similar predictions for optimal parameters and token scaling with FLOPs. All three approaches recommend scaling the model size and training data proportionally with the computing budget.
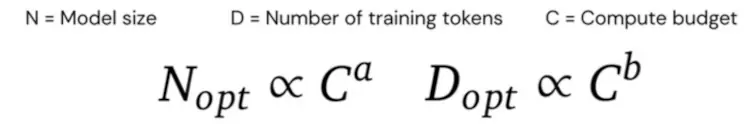
To validate their hypothesis, they trained a mode called Chinchilla with 70B parameters for 1.4T tokens and compared it with Gopher. Chinchilla has the same number of FLOPs, model architecture, and training setup as Gopher. The differences between the models are listed below:
- Chinchilla was trained on MassiveText (the same dataset as Gopher) but used a different subset distribution to account for more tokens;
- Chinchilla used AdamW instead of Adam to improve the language model loss and downstream task performance after fine-tuning;
- They trained Chinchilla without NFKC normalization using a modified SentencePiece tokenizer. 94.15% of tokens are the same as Gopher's;
- They saved a float32 copy of the forward and backward pass weights computed in bfloat16 - see lessons learned from this paper for further details.
Results: Chinchilla consistently and significantly outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing (530B) NLG on a variety of downstream evaluation tasks (language modeling, MMLU, reading comprehension, BIG-bench, Common sense and Closed-book question answering):
- A highlight is that Chinchilla outperforms Gopher by 7% on the MMLU benchmark, achieving a cutting-edge average accuracy of 67.5%.
To read more details, go to Training Compute-Optimal Large Language Models.
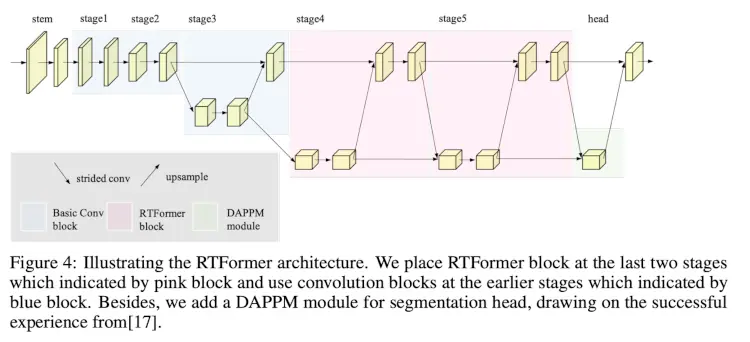
2. RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer
- Author: Wang et. al.
- Link to paper.
- Link to extended summary
TL;DR: RTFormer is a dual-resolution transformer for real-time semantic segmentation. It uses GPU-Friendly Attention with linear complexity and discards multi-head. Cross-resolution attention spreads high-level knowledge from low-resolution branches to high-resolution branches more efficiently.
Problem: The transformer-based networks have shown impressive results in semantic segmentation. Yet for real-time semantic segmentation, pure CNN-based approaches still dominate in this field due to the time-consuming computation mechanism of the transformer.
Solutions: They proposed RTFormer, an efficient dual-resolution transformer for real-time semantic segmentation.
RTFormer block
Dual-resolution module which inherits the multi-resolution fusion paradigm and is composed of two types of attention along with their feed-forward network and arranged as a stepped layout.
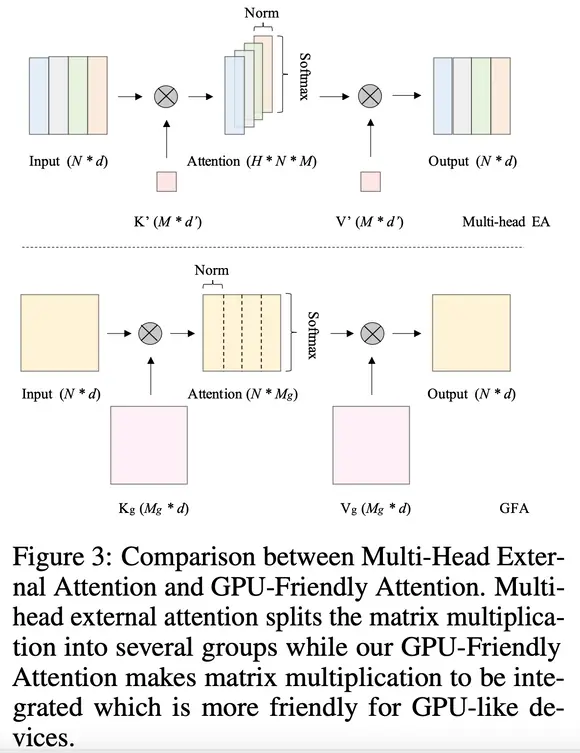
On the low-resolution branch, they have GPU-Friendly Attention (GFA) to capture high-level global context. This is derived from external attention, inheriting a linear complexity and using vanilla matrix multiplications instead of batch-wise matrix multiplication. And to maintain the capability of the multi-head mechanism, they use grouped double normalization. This allows learning more diverse information.
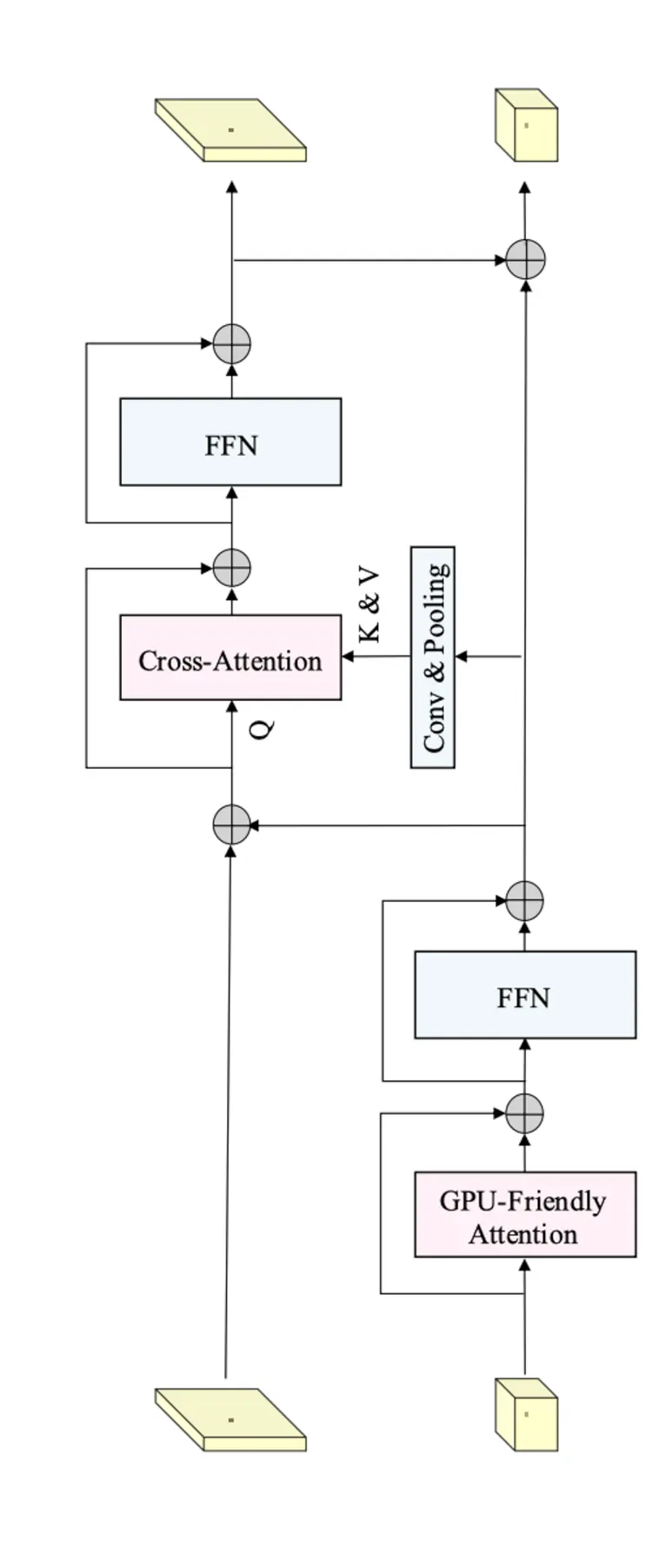
In the high-resolution branch, they introduce cross-resolution attention to broadcast the high-level global context learned from the low-resolution branch to each high-resolution pixel. The stepped layout fed more representative features from the low-resolution branch into the cross-resolution attention.
 <
<
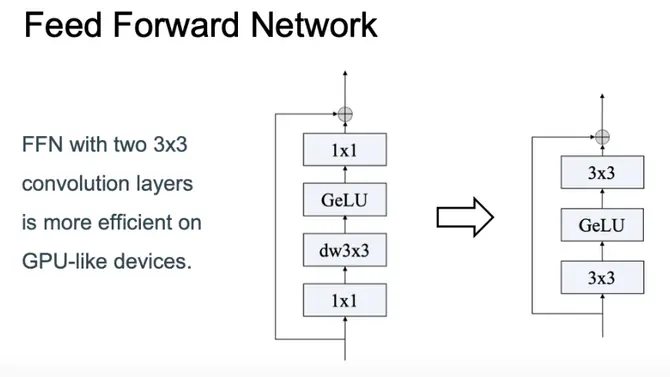
They also altered the Feed Forward Networks, as we can see below:
The overall network can be seen below.
3. Confident Adaptive Language Modeling
- Author: Schuster et. al.
- Link to paper
TL;DR: CALM aims to reduce the inference time of Large Language Models (LLMs). This is done by dynamically distributing various compute allocations per input and generation timestep.
Problem: Early exits use confidence estimates to dynamically reduce the inference time of a large transformer model. However, it involves several challenges that were tackled in this paper:
- What confidence measure to use;
- Connecting sequence-level constraints to local per-token exit decisions;
- Attending back to missing hidden representations due to early exits in previous tokens.
Solutions: In this work, they introduce Confident Adaptive Language Modeling (CALM), a framework for dynamically allocating different amounts of compute per input and generation timestep.
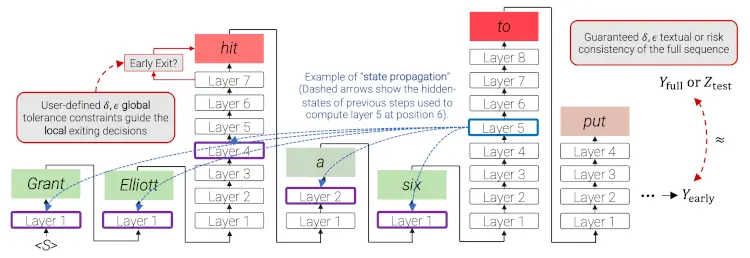
This is done such that you can use the same architecture that you trained on (no model distillation, so no gains in memory usage) but can only run the necessary layers to have a good enough representation (so boost inference response time, that's the goal).
This work is also motivated by recent findings on the existence of saturation events in LMs, where the top-ranked prediction is unchanged after some layer and is propagated upward.
Through theoretical analysis and empirical experiments on three diverse text generation tasks, they demonstrate the efficacy of their framework in reducing compute — potential speedup of up to ×3 — while probably maintaining high performance.
Early exit decoding involves several challenges that were tackled in this paper:
- What confidence measure to use;
- Connecting sequence-level constraints to local per-token exit decisions;
- Attending back to missing hidden representations due to early exits in previous tokens.
4. Self-Explaining Deep Models with Logic Rule Reasoning
- Author: Lee et. al.
- Link to paper
- Extended summary
TL;DR: SELOR adds self-explanation to a deep model for accurate predictions by predicting log rules to explain a model.
Problem: Pre-trained deep learning models in a wide range of tasks usually has a complex model design. This raises important questions about whether a deep model is ethical, trustworthy, or capable of performing as intended under various conditions.
Works on post-hoc explanations for black-box models that have already been trained do not change the model and hence preserve the predictive performance while providing the additional benefit of explainability. However, they have a high computational cost and may induce trust issues.

Solutions: Self-explaining models naturally solve these issues, making them an ideal choice when interpretability. These models can predict and explain simultaneously with a single forward propagation without any approximations or heuristic assumptions that decrease the faithfulness of explanations.
This paper proposes SELOR, a framework for upgrading a deep model with a Self-Explainable version with LOgic rule Reasoning capability. Their framework is inspired by neuro-symbolic reasoning, which integrates deep learning with logic rule reasoning to inherit advantages from both.
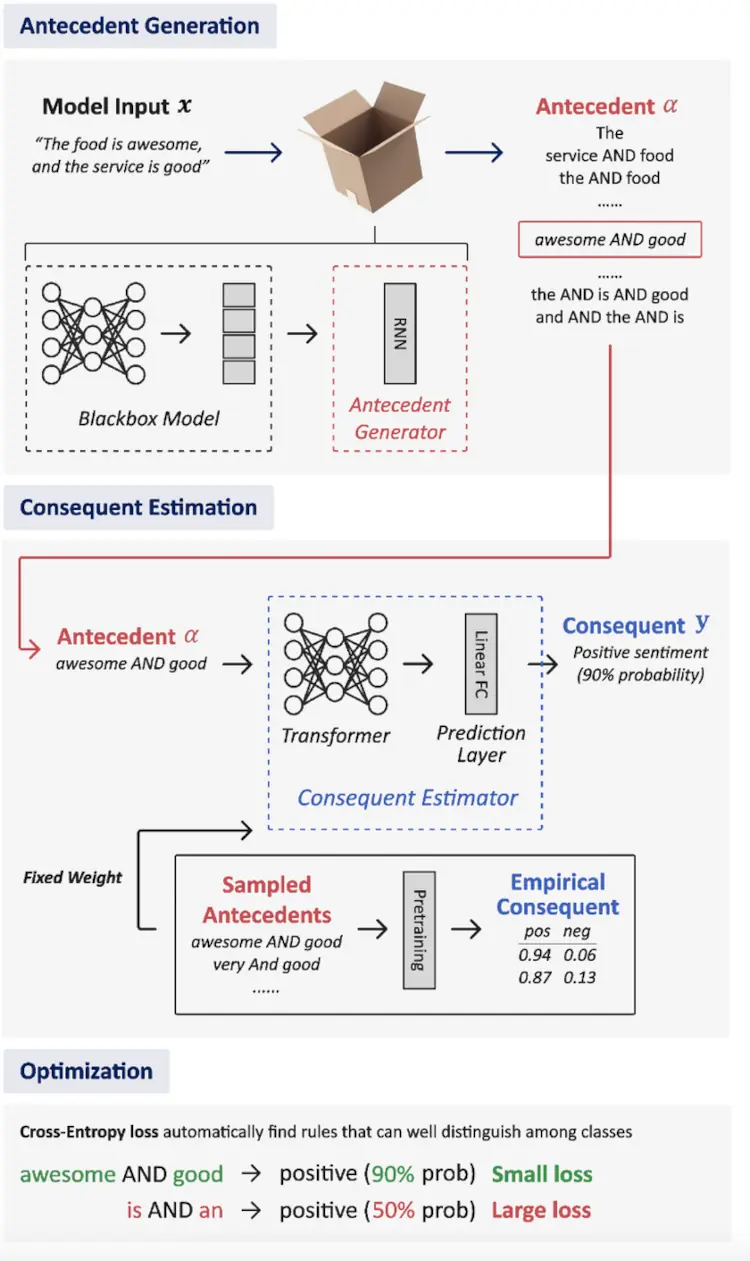
The main idea behind the SELOR model was to separate the model into two parts, as we can see in the image below:
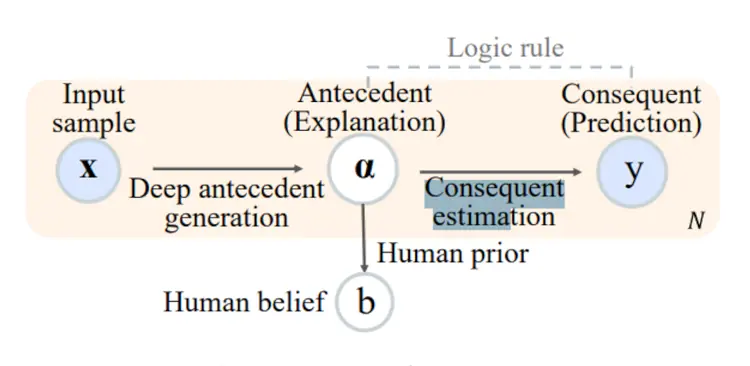
1. Antecedent generation
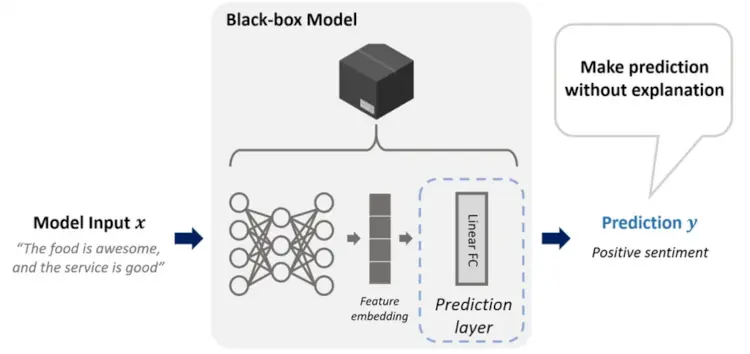
First, the Prediction layer was replaced by an Antecedent generator. The goal is to map the latent representation of input into an explanation instead of directly mapping to a prediction.
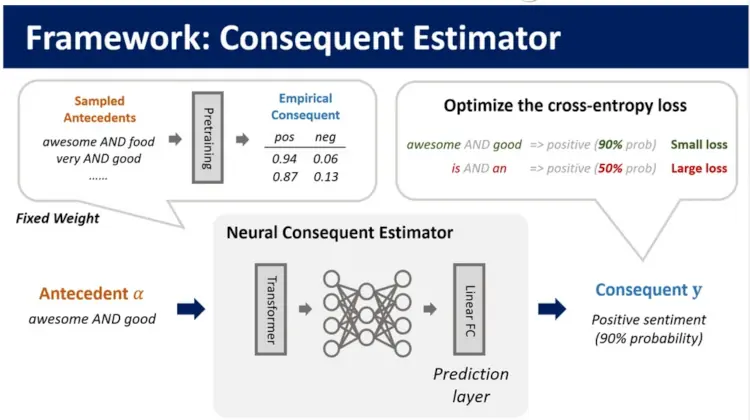
2. Consequent estimation
The Neural Consequente Estimator (NCE) is pre-trained to predict the consequent, in other words, the logic rule. Cross-entropy loss is used to optimize the probability predicted by the consequent estimator for the antecedents extracted by the antecedent generator during the model's training. The NCE only needs to be trained once for each dataset, and then it can be used for various deep models and hyperparameters.
3. General overview of the model
Coming Up Next
Thank you for reading!
If you can’t wait for my next blog post to learn more about our NeuroIPS’s takeaways, I invite you to join our weekly Reading Group discussions.
In this weekly meeting, we discuss the latest discoveries in the AI world. The Reading Group is open to external viewers and presenters, so if you want to attend or present something for discussion, follow the links in the "Join Us" section of the page!
In my next blog post, I’ll cover the following papers:
- Gradient Descent: The Ultimate Optimizer (*)
- ProcTHOR: Large-Scale Embodied AI Using Procedural Generation (*)
- A Neural Corpus Indexer for Document Retrieval (*)
- Training language models to follow instructions with human feedback
- Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding*
- Beyond neural scaling laws: beating power law scaling via data pruning (*)
- Locating and Editing Factual Associations in GPT
- STaR: Bootstrapping Reasoning With Reasoning
- UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
- BYOL-Explore: Exploration by Bootstrapped Prediction


