Overcoming Uncertainty: Conquering Replace Data
OutSystems has built-in accelerators to quickly bootstrap UIs using existing data. These accelerators are a great app development shortcut. This is the story of how the Replace Data feature was born.
It goes without saying that an application’s UI is one of its most important parts. A good UI can make or break your app’s success. In most cases, the UI is the starting point for an app's development, and when building a UI, there are usually two stages. During stage one, a design team designs UI mockups and constructs the style guides. In stage two, a team of developers uses the mockups and style guides to build the UI with HTML and CSS. The developers then connect the UI to the data, bringing it to life.
We decided that we’d take care of stage one, enabling OutSystems developers to use a pre-built UI. That way, they could skip the need for a dedicated design team. They’d create their screens in the platform, test the UI, then, later on, they'd add the business logic and the data. It would speed up their development, saving time and resources.
And so the Faster UI Development initiative was born. After many hours of researching and discussing, we defined the main goal: to provide the most acceleration possible to the most common type of developer: a recently trained developer with only a few months of experience. We were on a mission to reduce the time from development to publication. We also decided that the persona we were developing for would have a very specific profile. So, meet Scott, a newcomer to OutSystems. Scott is an enterprise developer; he's completed the training and is on his first project. He must apply the company's brand to everything he develops.
What Does Scott Need?
What would speed up Scott’s UI development? The first step was to provide him with UI templates. He’d pick a suitable template and bypass the first of the two steps. He would also be provided with some sample data, so he could immediately publish and test the template.
Great! Scott's templates include the sample data. He can now bootstrap an application, publish it, tweak it, and then demo it. Job done, right? Well, no. The screens include sample data, and at some point, Scott will have to load the real data. We could leave him to redo all the bindings and aggregates of the screens himself, but that wouldn’t be very fast (or fun). Instead, it was time to make it possible for him to change the data source and bindings not only in a screen created from a template with sample data but also in any screen with data. The name of the new feature was Intelligent Data Rewiring. Just kidding! It’s actually called Replace Data, because that’s what it does. It replaces the data in a screen with a simple drag and drop.
Paper Prototyping and Replacing Ideas
Before implementing the new feature, we needed to test our plan and confirm that we were on the right track. First, there were usability tests with paper prototypes. Inexperienced users were our testers, and we observed what they would choose to do. Most of the users dragged the entity they wanted and dropped it on the widget where they wanted it applied. This wasn’t the implemented behavior (but it did resemble existing behaviors).
What we learned from the usability tests gave us a starting point to start experimenting. And when experimenting, we like to go for it! We will pursue every wild idea, we will consider everything. There are no time or cost restrictions. Everything is possible! We broadened our horizons, and we’re confident we considered all possible solutions.
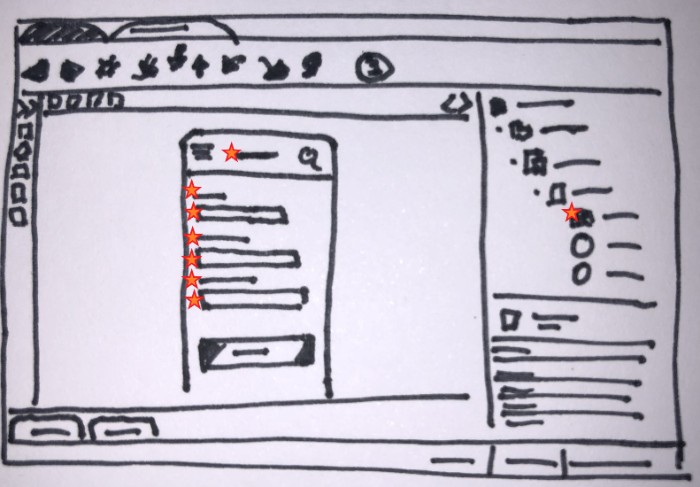
Dragging the entity was a straightforward and expected behavior. We already had accelerators that allow us to create a list or a form by dragging an entity to the screen. But there were other interactions to consider, like the context menu.
Defining the Interactions
It was time to narrow down the possibilities; we had to define where the interactions take place. Where would we drop the entity? Where would the context menu open?
The usability tests hadn't answered these questions, so we considered our options.
We could drag and drop the entity on three other targets: the widget, the screen, or the aggregate. What about the context menu? Because the context menus have the same targets, we decided to focus on where the interaction takes place. We also looked for differences. What varies depending on the target?
We identified three targets with data we wanted to replace: they were the entity, the aggregate, and the widget source. Replacing the entity would be like a find and replace operation. Replacing the aggregate would be a simple swap of one aggregate for another. To replace the widget source, we'd replace the entity inside that specific widget data source.
So we had a plan for handling the entities. The attributes were next. There were two options: manual or automatic matching. With manual matching, the developer would manually match all the relevant attributes, but that wouldn’t be very fast. To automatically match them, we use a heuristic approach. We'd use the attribute type and the relations between the entities to map them. After each replace, we’d need to fix the impact and change the bindings. For the new data to make sense, we'd have to change the text in the labels, the sorts, and variable types.
It was time to validate these potential solutions and figure out their feasibility. So, another set of paper mockups was tested with developers to discern the value of the solution and make sure we weren't completely off target. At the same time, we started to analyze the solutions to plan the implementation. We also estimated the required time and resources (cost). We had to consider the potential value and cost of every solution so we could make a final decision.
A Minimum Viable Product Per Sprint
It was now down to a few solutions; however, combining some of them could create even more solutions. We needed to decide what solution or solutions to implement; we couldn't do it all. We could choose a combination of solutions to maximize value and meet the deadline. We could choose low-cost solutions, so we could do the most and the overall value would be enough.
We needed to manage risk. Usually, a higher cost means higher value, but a larger investment also brings higher risk. There is no guarantee that, at later stages, we won't find shortcomings. And by then it would be too late to react. Alternatively, choosing the lower cost solution is also risky. We could finish the project and not add enough value. Just as with the higher cost solution, there wouldn’t be time to backtrack. We wouldn't have time to implement another solution to increase the value.
So what should we do? There is wisdom in the saying “virtue stands in the middle.” We decided to compromise and go for middle ground. We chose a single high-cost solution. The solution promised a high added-value and that was achievable in the time we had left. This would maximize the time we'd have for Early Access Program (EAP) feedback. We'd have more time to test and react to any issue we found.
By now you must have realized we value feedback as early as possible. To achieve this, we chose the hamburger method, because we love hamburgers! And so, we were able to deliver a small part of the feature in each sprint. We could test each small part and gather feedback from the stakeholders. We'd then incorporate what we learned in the next sprint. By doing this we minimized the risk of missing our target.
Testing, Testing, Testing!
After we tested, we tested again. When conducting usability tests and applying them to multiple scenarios, what’s vital is testing as often as possible, as soon as possible. Apply what you learn, improve, and fine-tune the solution, and then test it again. That way, when it's live and out to thousands of users, you can be confident that you delivered to a high standard.
We'd implemented all we'd proposed to do. Yet, the usability testing indicated there was room for improvement. To increase the value of what we were delivering, we revisited the solutions discarded earlier due to their cost/value ratio. We chose a couple that had the right value and that we could do in the remaining time.
A Little Context, A Lot More Insight
At this stage of development, mockups wouldn’t do the trick. We’d already implemented a lot of the feature and incorporated it into the product. Instead, we did a proof of concept (PoC) in the OutSystems development environment, integrated the working PoC into the product, and we put it to the test. We were expecting brilliant results that would make us feel very comfortable.
The tests revealed we hadn't improved as much as we expected and also raised a few red flags. It felt like a roller-coaster ride—one week we had the best feature in the world, and the next week we feared we were going to miss our target and crash spectacularly. But we kept our focus and decided to test the PoC again. We needed to go back to the beginning to make sure we hadn’t missed something.
We'll usually poach developers from other departments to be our testers. In the earlier testing, we'd only briefly explained the feature before asking the developers to use it. This time we reached out to a partner company. They provide OutSystems training and would be training developers to use the Replace Data feature in the future. Our own training department provided us with a training video they were developing that included this feature. In this round of testing, the poached users watched the training video. And based on what we learned, we ended up dropping the PoC and going with the initial approach. Giving the users a little more context made all the difference.
A Job Is Never Done: Continuous Improvement
The time had arrived; we’d released the feature. Job well done! Well… no. The job is never done. Gathering feedback from users enables us to continue improving and fine-tuning. Plus, there’s another tool in our tool-belt: telemetry. Telemetry gathers information about how our users use the feature after the release. It gave us valuable insights during the Early Access Program. We will continue to watch this data, to see how the feature is behaving in the wild. In the long run, we’ll also be keeping an eye out for new technology or different solutions that can boost or improve the Replace Data feature.
This journey taught us that it’s not easy to build something when there is no baseline to measure against. Yet, in the end, the sense of accomplishment is immense. Scott was essential, but at times, filtering all the feedback was exhausting. There were times we felt discouraged but we knew we had to focus and stay optimistic.
Speed is of the utmost importance. We iterated, experimented, and validated the ideas and solutions as fast as possible. We managed to avoid wasting time on solutions that could lead us nowhere. A discarded idea isn’t a failure; it’s an opportunity to gain knowledge about the problem you have on your hands.
After reading this, I bet you’re curious to try it out. Good news: you can download the new OutSystems 11 at no cost. What do you think? We’re always interested in hearing from you.


