.NET Core Migration — The Devil Was In The Tests
For the last several months, OutSystems has been investing in rebuilding a cross-platform Service Studio, which aims at providing a native experience, not only for Windows, but also for MacOS users. Prior to this huge endeavor, in 2019, teams started running their first .NET Core experiments, mainly to assess its real value and fit to our product vision and roadmap. It did not take long to shift gears and adopt it as our choice from a technology stack point of view.
As first test libraries underwent the migration process, something became pretty obvious, pretty soon: regression tests were not running. We had a small crisis on our hands.
Tests, the Unloved Relatives
Going back a couple of months, in order to properly prepare our product and organization for such a migration, clearly estimate the effort required, and concretely define value milestones, we used analyzer tools like the ones described by my fellow colleagues João Malés and César Afonso in their articles.
These analyzers provide you with extremely useful and detailed information on the compatibility of your projects to .NET Core, as well as their dependencies. As a starting point, it is a huge advantage to grasp how complex and time consuming the refactoring ahead might be. Nevertheless this information is valid from a compile/build perspective only — the biggest unknown is actually when pieces come together in runtime.
For that reason, we fiercely and incrementally aimed at reaching a minimum viable product (MVP) as fast as possible. That would allow us to mitigate the risk of finding unpleasant surprises while executing the code.
While this approach made sense from a risk mitigation standpoint, the narrowed scope and focus in actual product code misled and blocked a holistic view over the whole migration problem, thus leaving us somewhat blind to other areas which were equally important. It’s not uncommon to see many architectural considerations and concerns being discussed product/feature-wise in early stages of a project, leaving other complementary disciplines in the DevOps realm aside or to second place, as kind of poor and unloved relatives.
One could argue that, to a certain extent, we neglected and underestimated the impact we would have in our build system and Continuous Integration/Continuous Delivery (CI/CD) pipeline, especially considering the nature of what we were doing. In fact, tests are a level above in terms of code dependency, as they reference the actual product code under test. Therefore, they do introduce an additional level of complexity in such a migration.
We were still at early stages of the project, so it was time to identify the underlying problems and draft an attack plan to address them.
Technical Debt, the Anchor
Code migrations of this nature tend to highlight something that we sometimes sweep under the carpet: technical debt.
It comes in many forms and flavors. Traditionally it revolves around prioritizing delivery speed over code completeness, excellency, quality and reliability, which in turn would result in additional future costs, especially with maintenance and later refactoring. This implies a voluntary and conscious decision from a person, a team, a department, which is not always the case when it comes to technical debt. It might simply be a consequence of code changes done by several different people throughout time, with different backgrounds and knowledge of the system design and principles, increasing the complexity and brittleness as new tweaks keep getting added. In other cases, like long-lived applications, architectural decisions or certain components might simply have become outdated and no longer comply with new industry standards or meet the necessary requirements.
While there is greater control over self-proprietary code owned by the company — which the teams can at any point refactor — the truth is that a considerable amount of functionality delivered in big software projects is built on top of third party libraries, be those open source or vendor-specific. And rightfully so, as often there is very little value in reinventing the wheel. Using libraries saves time and gives room for teams to really focus on what matters in terms of core functionalities.
However, like everything in life, there are drawbacks, the biggest of which is the fact that a dependency to an external party is created. This entails some risks related to the support of the library (or lack thereof), security, licensing and version control, for instance.
Third-party libraries, if not managed properly, are a direct source of technical debt, as they can become outdated very quickly. For that reason, it is paramount that teams have an aggressive update policy over the different dependencies in their products and review them periodically.
Houston, We Have A Problem
Test projects usually rely heavily on these external dependencies, due to the use of test frameworks, such as NUnit or XUnit, mocking frameworks like Moq or NSubstitute, reporting tools, and code coverage plugins.
Within Engineering at OutSystems, our unit test population is no different.
Being a product mostly built in C#, we have been using NUnit in house for many, many years as our framework of choice. On the one hand, NUnit enables developers to run tests directly from Visual Studio while working on a specific feature or bug fix. On the other hand, from a CI/CD standpoint, tests can also be executed in test agents directly from the command-line using a console runner.
Internally, we had been making use of NUnit’s extensibility mechanisms to account for specific use cases and customizations we needed in the CI/CD pipeline, so in fact we were using a custom version of the console runner and some add-ins to fully support all required operations.
By the time we started the migration to .NET Core, our code was referencing NUnit 2.6.3, which dated back to 2013 (!). Besides being a rather central piece in our test population that was completely and utterly outdated functionality-wise, the first version of .NET Core was released in mid-2016. The problem was now obvious: our NUnit version did not support .NET Core, at all.
The Challenge Ahead
The solution to the problem at hand seemed rather simple: we “just” needed to upgrade NUnit.
However NUnit 3 had changed its architecture and extensibility mechanisms dramatically, introducing a considerable amount of breaking changes and turning the upgrade into a daunting activity. Furthermore, our reality brought yet another level of complexity to the table.
For the last few years, Engineering teams adopted a trunk-based development model, with its own set of advantages and disadvantages. Each commit in the trunk triggers the dedicated CI/CD pipeline, which in turn builds the corresponding solution and runs tens of thousands of automated regression tests, immensely tied to the aforementioned NUnit customizations and an outdated framework that suffered deep changes, even to its execution profile.
These pipelines provide an automated build, test and delivery process to unarguably the largest parts of the OutSystems portfolio: the Platform Server and ServiceStudio.
While the Platform Server is the component that orchestrates all runtime, deployment, and management activities for all applications, Service Studio is the Integrated Development Environment that connects to the Platform and empowers OutSystems developers to make use of low-code to develop complex, rich, and modern applications.
These two very big, complex pieces share the same repository, following a mono repo strategy. They have become inextricably intertwined in common areas of the code, with two different builds, distinct CI/CD pipelines, and worlds apart release cadences. A highly complex software ecosystem that is supported by dozens of active product teams, daily changing and evolving the code base.
Another common ground for these two products was their dependency to NUnit, so performing any sort of upgrade to NUnit would entail unforeseen consequences on Platform Server’s CI/CD pipeline as well. That was neither desirable, nor acceptable.
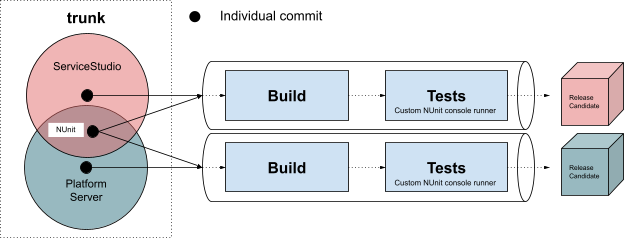
An additional and highly relevant constraint was the unpredictability of the whole situation. Teams were completely focused on the product-side migration of projects and did not account for the unforeseen need to perform this upgrade. Teams’ focus was spread among several different tracks.
So the real question was: how could we upgrade NUnit’s version for ServiceStudio only, thus unblocking the .NET Core migration that was underway, without any impact to other systems and respective CI/CD pipelines?
Setting The Principles
Regardless of the changes most certainly required, and given the trunk-based development model in place, it was extremely important to exercise a set of principles which are of second nature to us:
- No big bang changes. That is, perform changes in baby steps, in an incremental fashion. Start small, learn, and scale from that;
- Zero impact on everyone else’s work, no hiccups in the CI/CD pipeline;
- Focus on the use cases that would unblock the .NET Core migration.
So, go small and incrementally, with no negative impact at all. Kind of ambitious, right?
The Approach
The first step to enable .NET Core — upgrading NUnit version — consisted, in high level blocks, of the following:
- Refactoring our internal extension to be compatible with the new NUnit version;
- Pushing the new NUnit version and extension to the product’s code;
- Creating a new version of the console test runner;
- Integrating everything into the CI/CD pipeline.
1. Extension
Considering there was a separate repository for this extension, which included a set of unit tests, the work pretty much consisted of targeting the new NUnit version by changing its dependencies accordingly and iteratively working on fixing every failing unit test from that point on.
Prior to this whole endeavour, the extension’s binaries were fed and committed directly in the main repository. These binaries would then be directly referenced by each product (Service Studio and/or Platform Server).
We took the opportunity to deal with what was legacy code and created a dedicated CI/CD pipeline in our Azure DevOps to validate the extension’s integrity on commit. Furthermore, the new version was now being generated as a NuGet package that could easily be fetched by other parts of the product.
2. Pull NUnit and Extension To Test Projects
At this point, contrary to our principles and due to the fear of impacting other teams, we decided to branch out without really considering other alternatives, like branching by abstraction. Simply put, we were suffering a bit from tunnel vision syndrome: we knew the goal (NUnit3) and the path (upgrade) seemed clear. At the same time, the unplanned nature of the upgrade led us to forcefully split our focus between everything that was going on, in a best effort fashion.
Simultaneously, there were a lot of breaking changes from NUnit 2 to NUnit 3, and to a certain extent, we weren’t fully aware of the side effects of performing the upgrade. Would tests produce the same outcome? Would we suddenly have many failures we needed to address?
By looking at NUnit’s release notes, we could see some changes in the SetUp and TearDown hooks at the class level for instance. This was a bit scary at first, as many tests relied on specific initialization code running in these methods on base classes. Another apparently meaningless change was the fact that each test assembly now needed to explicitly reference the NUnit.Framework, or tests would not be identified. This could potentially make some of our tests disappear and not be executed in the CI/CD pipeline at all.
Given that we were working on a separate branch, we simply performed the upgrade on each test project and dealt with the thousands of build warnings / errors that emerged from the process. By the end of these iterations, we reached the first milestone and started executing tests in Visual Studio.
However, our confidence levels were still very low, as we could not run our commits through the CI/CD pipeline. Because of this, our visibility was quite limited to the manual validations we had been performing up to that point.
3. The Console Runner
NUnit provides an off-the-shelf console runner (NUnit Console) with a set of basic functionalities to enable test automation and integration with other systems. For historical reasons, we extended the command-line capabilities in order to support additional use cases that were substantially relevant in our CI/CD pipeline, namely:
- Test metadata discovery — being able to extract all attributes and information pertaining each unit test in the test binaries;
- Inclusion and exclusion of tests based on text files;
- Resiliency mechanisms (retries, hang prevention, test segmentation) to address flakiness and potentially compromising problems;
- Support for specific types of UI testing.
The upgrade once again brought a set of challenges. The command-line arguments now differed substantially, some APIs changed dramatically, and so did the visibility of internal classes we needed to reference.
We worked in an incremental fashion to regain feature parity on the new test runner, validating our changes against the branch we had created with our tests, which was now targeting NUnit 3.
Some problems could be handled applying good design principles and coming up with robust alternative mechanisms. Other required less pretty, although effective (hammer alert) solutions, like using reflection to invoke specific inaccessible properties or methods.
We did what we do best at OutSystems (disclaimer, the Pareto Principle), which is to compromise when strictly needed and aim for 80% of the value with 20% of the effort.
4. Integration with the CI/CD Pipeline
By the time we had all the pieces assembled and working with NUnit 3, weeks had gone by, for basically two reasons: the amount of work involved, and lack of focus due to other activities running at the same time.
Branching out allowed us to work autonomously and in a (bit of a) brute force manner, speeding up the research process and fully understanding the impact of the upgrade in our ecosystem. However, our branch was now considerably distant from the trunk, where everyone else was working. Merging was by no means a trivial process; the differences were just too many to be handled properly, with hundreds of conflicts blocking the operation and definitely clashing with our zero-impact principle.
One could advocate that a more thoughtful approach involving frequent merges from the trunk to our branch would prevent us from hitting that wall — and to a certain extent, that is true. Nevertheless one must also account for effort and time put in on a daily basis to ensure parity between branches. Above all, our main focus with this branch was, subconsciously, to assess the impact of the upgrade in all bits and pieces of the CI/CD pipeline. And, from that perspective, we did succeed: we had a brand new version of the add-in and the console test runner ready to be consumed by the tests and the pipeline.
But how could we deliver these changes incrementally to our main branch? We needed to go back to the drawing board…
One Step Back, Two Steps Further
The roadblock in merging our changes required further investigation and research on our part, in order to understand a viable way to adhere to our principles. As part of this, we thoroughly revised NUnit’s release notes once more, and spotted a specific version that definitely caught our attention: 2.6.5.
“This is the first release of NUnit under the NUnit Legacy project. It primarily aims at providing features that will assist users in making their tests more compatible with NUnit 3.”
Besides bug fixing, it mainly served as a bridge between NUnit 2 and NUnit 3, by adding warnings to soon-to-be deprecated features, complementing it with NUnit 3 new attributes, providing compatibility reports, and making new command-line arguments available. All in all, this intermediate version acted as facilitator of the upgrade. What once were breaking changes, were now signaled as such without actually breaking the code, giving us the opportunity to slowly and incrementally perform the changes across all test projects, directly in the trunk and having full control over the impact in the CI/CD pipeline.
Even considering that 2.6.5 was a real and concrete step for us to reach NUnit 3, the elephant in the room was now staring at us. As mentioned earlier, both Service Studio and Platform Server referenced the same NUnit binaries in the mono repository as a shared dependency. So separately evolving both CI/CD pipelines in order to support two different NUnit versions was not possible.
Furthermore, and to actually make the situation worse, this tight coupling had actually proliferated into other shared, central test libraries used by both systems.
A major refactoring was needed to unblock the upgrade:
- Review the common test utilities, segmenting and isolating Service Studio’s and Platform Server’s specific logic into two distinct utility projects.
- Remove all NUnit dependencies from common projects, thus decoupling both systems in terms of NUnit dependencies.
- Reference through PackageReference (NuGet) NUnit version 2.6.5 in Service Studio projects.
- Keep the reference to NUnit old binaries in Platform Server projects.
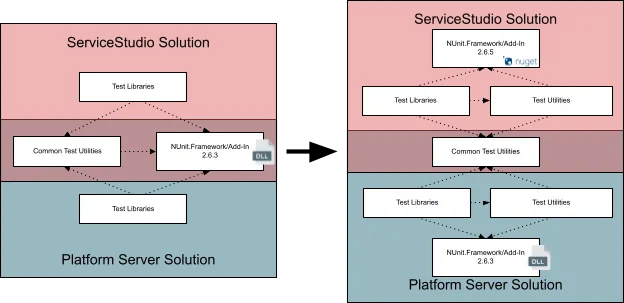
Because we were within the same major version of NUnit, creating matching versions of the add-in and the console runner was a pretty straightforward task as well, so all the pieces came together.
As a result of this reshuffling, we were now able to incrementally bump NUnit’s version in Service Studio’s CI/CD pipeline to 2.6.5, independently of the Platform Server. More than that, we did everything directly in the trunk, with zero impact. No pipeline downtime. No tests failing due to unforeseen reasons. Just like a standard, small, localized commit.
It is also noteworthy that, by then, the code base was entirely compatible with all the compile-time breaking changes introduced by NUnit. In other words, upgrading to NUnit 3 implied simply raising the version of the NuGet packages being fetched by Service Studio during its build process.
Lo and Behold, NUnit 3
Our whole approach aimed at mitigating the risk involved in this upgrade. Even though we prevented all build problems and performed several validations in the branch we had created for that purpose, the moment of truth, the eureka moment had arrived.
It was finally time to upgrade to NUnit 3 and make sure all pieces of the puzzle worked as one, with no runtime surprises.
Apart from a couple dozen tests that escaped our validations and started failing due to a valid breaking change listed in NUnit’s release notes — related to the fact that test execution would no longer affect the CurrentDirectory property of the process — the adopted strategy really paid off at the end.
We thoroughly validated the results coming out of the CI/CD pipeline, by comparing the list of executed tests, the list of outputs, the execution times, and going through all monitoring and alerts we use to troubleshoot occurrences in the pipeline.
With an almost seamless upgrade to a major, central piece of the code base, we managed to recover years of lag and technical debt and almost go unnoticed in our CI/CD system. Moreover, we had finally opened the door to .NET Core.
Running Tests with .NET Core
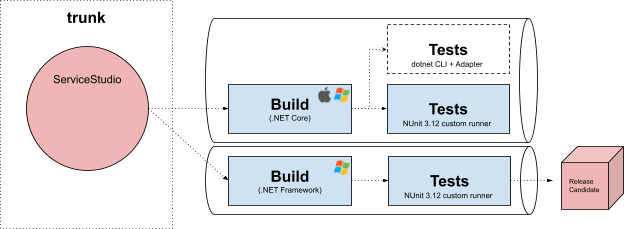
Just like we did with other relevant Service Studio projects, test projects had to be adapted in order to become multi-target (.NET Framework and .NET Core), meaning different builds compatible with those frameworks and distinct output artifacts. Because we added NUnit 3 support and it is compatible with different runtimes by default, namely .NET Framework and .NET Standard, being the latter referenceable by .NET Core test projects, no further changes were required from that standpoint to have test projects build successfully, as everything was handled by MSBuild and NuGet automatically. That wasn’t necessarily the case with our internal NUnit extension though, which needed to be changed to multi-target and produce as build output .NET Standard libraries as well.
In a nutshell and after these tweaks, we were now able to execute tests in Visual Studio. However, just like before, with NUnit 3, the missing piece of the puzzle was again the ability to execute tests in test agents.
The de facto way to execute unit tests in .NET Core is to resort to the dotnet Command-Line Interface (CLI), relying on each specific Test Adapter (e.g. NUnit3TestAdapter, XUnit.Runner.VisualStudio, MSTest.TestAdapter) to execute the unit tests, built on top of the corresponding framework (e.g. NUnit.Framework, XUnit, MSTest.TestFramework).
By running the dotnet test command, a test host application is hosted for each indicated project / library and executes the discovered tests using the appropriate test adapter. The CLI has many optional parameters and configuration possibilities, thoroughly described in Microsoft’s documentation. After going through the documentation and exploring the options, it was pretty clear that the custom use cases our console runner supported (test metadata, etc) were not covered in the available API.
Additionally, our recent version of the console runner, built on top of NUnit 3, was compatible with the .NET Framework only. And now comes the tricky part: by the time we were at this stage, the standard NUnit Console Runner had no support (nor foreseen work to add it) to the execution of .NET Core tests.
Note: meanwhile a couple of versions were already released (Aug 2020) for the NUnit.ConsoleRunner package, but it is still in a Beta stage.
So essentially we hit the last roadblock in this continuous delivery journey to the .NET Core test execution: either we opted for the standard CLI and weighted the limitations against the need to actually change our CI/CD pipeline architecture — risk wise, something we really wanted to avoid — or we somehow found a shortcut to add .NET Core support to the Console Runner.

Our principles heavily influenced this decision, so from a CI/CD pipeline perspective, we wanted to minimize entropy. So we went for the latter.
Porting the console runner to .NET Core involved some serious shortcuts and less catchy, good-looking decisions, but we are, and were, extremely outcome-oriented.
The lack of support from the standard NUnit Console Runner forced us to build custom versions of some of the libraries, adapting them to our needs. Upgrading the chain of dependencies, which we had customized, was a very painful process. New concepts in the .NET Core reality, like the deps.json file and the runtimeconfig.json files, introduced additional problems in running third party applications against our product libraries. Relevant NUnit configurations, like the PrivateBinPath, often used to add additional probing paths for test assemblies (plugins for instance), were now being ignored and forced us to find plausible workarounds. Ultimately, the number of problems we were identifying as time moved on and new projects kept getting added made us rethink our approach.
In a way, we were perpetuating what partially led us to undergo all these changes. The customizations built on top of third party applications, tailored to unique internal use cases, would continue dragging us in future upgrades. It was one of those cases: the simpler, the better.
We revisited every use case once again and realized we wouldn’t be able to wipe off all technical debt in the form of customizations, but there was a way to considerably simplify the approach, minimize future costs with upgrading, and contribute to the better separation of concerns: a custom version of the NUnit3TestAdapter.
The dotnet CLI allows for additional, custom parameters to be passed on as arguments, which can be processed by the test adapter. By forking its repository and complementing it with additional logic, we partially covered our requirements, namely everything developers would require in their activities, like test inclusion / exclusion through input files.
dotnet test ServiceStudio.Tests.dll -- OutSystems.InclusionList=”inclusion_list.txt”
Everything CI/CD pipeline-specific, like resilience mechanisms (retries, hang detection), was transferred to the pipeline scripts, already responsible for controlling the flow of execution and managing test agents.
The final step was to integrate all of these changes into the pipeline. Again, we didn’t want to drop the ball at the end, so the same principles were applied. Our working, yet quirky solution, with the ported custom NUnit console runner, was used to our advantage and served as a baseline for comparison with the new solution.
A shadow stage in the pipeline allowed us to simultaneously run the old and the new approach and fine tune whatever was necessary. At the end, the only thing required was to remove the old stage and replace it with the new one — a frictionless, seamless transition that fully enabled .NET Core test execution in the pipeline.
Key Takeaways
What started off as a small crisis in a hallway chat ended up becoming a true continuous delivery journey that lasted several months. It was one of those “changing the wheels on a moving car” type of challenges that combined two spicy ingredients. On the one hand, the pieces that we were touching were highly critical, absolutely core and vital to Engineering processes. On the other hand, the time factor was crucial, as the motion to .NET Core was real and speeding up, with teams actively migrating code and projects each day. Because our friend Murphy always strikes, parental leaves were also coming up.
Even though some mistakes were made, we managed to adhere to the established principles and keep the impact to a bare minimum, while delivering the desired outcomes and clearing the way for the .NET Core migration in a timely manner.
Along the way, we derived many lessons and insights, ending up collecting a set of good principles and practices that remain as takeaways of our work.
Focus is key. Best effort won’t cut it in such critical undertakings. It makes you fall short in thinking about the big picture. The lack of focus and context switching between tasks hinders your productivity and could potentially compromise your whole approach to the problem. Dedicate, commit, and plan time to your critical assignment.
Adopt progressive rollouts. Introducing your changes in a highly incremental, controlled approach is an extremely effective way to mitigate associated risks. Always challenge the big bang approach and advocate progressive rollouts. Doing so might be harder at first, but it will pay off in the long run. Take advantage of branching by abstraction, shadow validation systems (pre-production environments, hidden pipelines/stages).
Baby steps will get you to your goal as well. Sometimes taking intermediate steps is a lot easier and controlled than jumping or making a single big step, yielding the same exact outcome. Correctly decomposing problems will make a huge difference in the way you approach the solution, as it transforms big puzzles into smaller, more tangible and manageable pieces to assemble.
Branching out is OK, but only if short-lived. Branches are an extremely useful tool, but the more time a branch diverges from the main branch, the more effort it will take to merge your changes. Finding a sweet spot is crucial to effectively managing the work you put into keeping a synchronization between both branches.
The 1% rule. This is one of the most important ones; it’s how you make a difference in the long run. Create a habit to perform minor improvements on a daily basis. This is particularly relevant in tackling technical debt that hinders your agility and speed. It’s easier to keep track of the debt with new features, but for older, legacy code, a continuous improvement mindset must be present.
Revert is your best friend. There is a strange tendency to avoid reverting changes that caused entropy in a specific system, or CI/CD pipeline. People tend to focus on forward fixing, addressing the underlying issue, then going back in time and dealing with it in an offline manner, in their local machine. Reverting is the fastest way to heal up from a toxic commit and release the author from any kind of pressure to deal with the problem.
Don’t spare in your local validations. The “it works on my machine” syndrome. As soon as you press that commit button, the changes are underway and might impact a lot of people. Take that into consideration and exhaustively try to validate everything you can while you are still developing stuff.
20% of your efforts will produce 80% of your work. The Pareto Principle is extremely important in making your work relevant and meaningful to you and your organization. Expecting perfection and completeness is utopic in the majority of cases. Be sure to focus on the most relevant, impactful changes that allow you to reach the majority of the desired outcomes, with the least amount of effort. Finding a balance is hard, but decision making and compromising is key to success.
Always prepare for the worst. There are always unknowns when it comes to software development. Being overly optimistic can lead to unrealistic approaches that yield very bad results and lack of preparation. Expecting impact is not about being afraid to fail, it’s quite the opposite. It’s much rather about knowing how to react, and doing it very fast and effectively.




