Web Scraping Made Easy: The Full Tutorial
NextStep 2019 was an exciting event that drew professionals from multiple countries and several sectors. One of our most popular technical sessions was on how to scrape website data. Presented by Miguel Antunes, an OutSystems MVP and Tech Lead at one of our partners, Do iT Lean, this session is available on-demand. But, if you prefer to just quickly read through the highlights…keep reading, we’ve got you covered!
As developers, we all love APIs. It makes our lives that much easier. However, there are times when APIs aren’t available, making it difficult for developers to access the data they need. Thankfully, there are still ways for us to access this data required to build great solutions.
What Is Web Scraping?
Web scraping is the act of pulling data directly from a website by parsing the HTML from the web page itself. It refers to retrieving or “scraping” data from a website. Instead of going through the difficult process of physically extracting data, web scraping employs cutting-edge automation to retrieve countless data points from any number of websites.
If a browser can render a page, and we can parse the HTML in a structured way, it’s safe to say we can perform web scraping to access all the data.
Benefits of Web Scraping and When to Use It
You don’t have to look far to come up with many benefits of web scraping.
- No rate-limits: Unlike with APIs, there aren’t any rate limits to web scraping. With APIs, you need to register an account to receive an API key, limiting the amount of data you’re able to collect based on the limitations of the package you buy.
- Anonymous access: Since there’s no API key, your information can’t be tracked. Only your IP address and cool keys can be tracked, but that can easily be fixed through spoofing, allowing you to remain perfectly anonymous while accessing the data you need.
- The data is already available: When you visit a website, the data is public and available. There are some legal concerns regarding this, but most of the time, you just need to understand the terms and conditions of the website you’re scraping, and then you can use the data from the site.
How to Web Scrape with OutSystems: Tutorial
Regardless of the language you use, there’s an excellent scraping library that’s perfectly suited to your project:
- Python: BeautifulSoup or Scrapy
- Ruby: Upton, Wombat or Nokogiri
- Node: Scraperjs or X-ray
- Go: Scrape
- Java: Jaunt
OutSystems is no exception. Its Text and HTML Processing component is designed to interpret the text from the HTML file and convert it to an HTML Document (similar to a JSON object). This makes it possible to access all the nodes.
It also extracts information from plain text data with regular expressions, or from HTML with CSS selectors. You’ll be able to manipulate HTML documents with ease while sanitizing user input against HTML injection.
But how does web scraping look like in real life? Let’s take a look at scraping an actual website.
We start with a simple plan:
- Pinpoint your target: a simple HTML website;
- Design your scraping theme;
- Run and let the magic happen.
Scraping an Example Website
Our example website is www.bank-code.net, a site that lists all the SWIFT codes from the banking industry. There’s a ton of data here, so let’s get scraping.
This is what the website looks like:
If you want to collect these SWIFT codes for an internal project, it will take hours to copy it manually. With scraping, extracting the data will take a fraction of that time.
- Navigate to your OutSystems personal environment, and start a new app (if you don't have one yet, sign-up for OutSystems free edition);
- Choose “Reactive App”;
- Fill in your app’s basic information, including its name and a description of the app to continue;
- Click on “Create Module”;
- Reference the library you’re going to use from the Forge component, which in this case is the “Text and HTML Processing” library;
- Go to the website and copy the URL (here's an example). We’re going to use Portugal as a baseline for this tutorial;
- In the OutSystems app, create a REST API for integration with the website. It’s basically just a “get request”, and place the copied URL;
- If you noticed we have the pagination offset already present in the URL, it’s the “/100” part. Change that to be a REST input parameter;

- Out of our set of actions, we’ll use the ones designed to work with HTML, which in this case, are Attributes or Elements. We can send the HTML text of the website to these actions. This will return our HTML document, the one mentioned before that looks like a JSON object where you can access all the nodes of the HTML.
Now we can create our action to scrape the website. Let’s call it “Scrape”, for example.
- Use the endpoint previously created, which will gather the HTML. We’ll parse this HTML text into our document;
- Going back to the website, in Chrome, right-click on the page where the content is that you’d like scraped. Click on “Inspect” and in the subsequent section, identify the table you’d like to scrape;
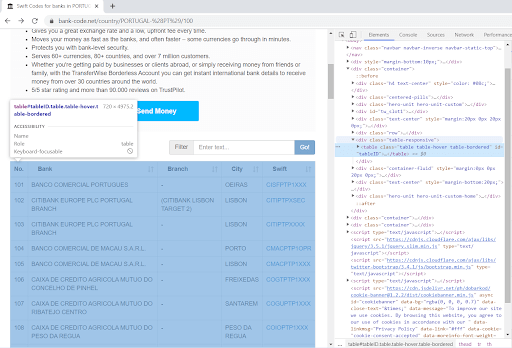
- Since the table has its own ID, it will be unique across the HTML text, making it easy to identify in the text;
- Since we now have the table, we really want to get all the rows in this table. You can easily identify the selector for the row by expanding the HTML till you see the rows and right click in one of them - Copy - Copy Selector, and this will give you “#tableID > tbody > tr:nth-child(1)” for the first row. And since we want all of them, we’re going to use “#tableID > tbody > tr”;
- You have now all the elements for the table rows. It’s time to iterate all rows and get to select all the columns;

- Now, select the column’s text, using the HTML document and the Selector from the last action, in addition to our column selector: “> td:nth-child(2)” is the selector for the second column which contains the Bank Name. For the other columns, you just need to iterate the “child(n)” node.
Since you have scraped all the information, check if you already have the code on our database. If we have it, we just need to update the data. If we don’t have it, we’ll just create the record. This should provide us with all the records for the first page of the website when you hit 1-Click Publish.
The process above is basically our tool for parsing the data from the first page. We identify the site, identify the content that we want, and identify how to get the data. This runs all the rows of the table and parses all the text from the columns, storing it in our database.
For the full code used in this example, you can go to the OutSystems Forge and download it from there.
Web Scraping Enterprise Scale: Real-Life Scenario - Frankort & Koning
So, you may think that this was a nice and simple example of scraping a website, but how can you apply this at the enterprise level? To illustrate this tool’s effectiveness at an enterprise-level, we’ll use a case study of Frankort & Koning, a company we did this for.
Frankort & Koning is a Netherlands-based fresh fruit and vegetable company. They buy products from producers and sell them to the market. As these products trade in fresh produce, there are many regulations that regulate their industry. Frankfort & Koning needs to check each product that they buy to resell.
Imagine how taxing it would be to check each product coming into their warehouse to make sure that all the producers and their products are certified by the relevant industry watchdog. This needs to be done multiple times per day per product.
GlobalGap has a very basic database, which they use to give products a thirteen-digit GGN (Global Gap Number). This number identifies the producer, allowing them to track all the products and determine if they're really fresh. This helps Frankort & Koning certify that the products are suitable to be sold to their customers. Since Global Gap doesn't have any API to assist with this, this is where the scraping part comes in.
To work with the database as it is now, you need to enter the GGN number into the website manually. Once the information loads, there will be an expandable table at the bottom of the page. Clicking on the relevant column will provide you with the producer’s information and whether they’re certified to sell their products. Imagine doing this manually for each product that enters the Frankort & Koning warehouse. It would be totally impractical.
How Did We Perform Web Scraping for Frankort & Koning?
We identified the need for some automation here. Selenium was a great tool to set up the automation we required. Selenium automates user interactions on a website. We created an OutSystems extension with Selenium and Chrome driver.

This allowed Selenium to run Chrome instances on the server. We also needed to give Selenium some instructions on how to do the human interaction. After we took care of the human interaction aspect, we needed to parse the HTML to bring the data to our side.
The instructions Selenium needed to automate the human interaction included identifying our base URL and the "Accept All Cookies" button, as this button popped up when opening the website. We needed to identify that button so that we could program a click on that button.
We also needed to produce instructions on how to interact with the collapse icon on the results table and the input where the GGN number would be entered into. We did all of this to run on an OutSystems timer and ran Chrome in headless mode.
We told Selenium to go to our target website and find the cookie button and input elements. We then sent the keys, as the user entered the GGN number, to the system and waited a moment for the page to be rendered. After this, we iterated all the results, and then output the HTML back to the OutSystems app.
This is how we tie together automation and user interaction with web scraping.
These are the numbers we worked with, with Frankort & Koning:
- 700+ producers supplying products
- 160+ products provided each day
- 900+ certificates - the number of checks they needed to perform daily
- It would’ve taken about 15 hours to process this information manually
- Instead, it took only two hours to process this information automatically
This is just one example of how web scraping can contribute to bottom-line savings in an organization.
Still Got Questions?
Just drop me a line! And in the meantime, if you enjoyed my session, take a look at the NextStep 2020 conference, now available on-demand, with more than 50 sessions presented by thought leaders driving the next generation of innovation.




